链表
相似解法题目多元组
双指针:< BM5 合并 k 个已排序的链表,BM6 判断链表中是否有环, BM7 链表中环的入口点,BM8 链表中倒数最后 k 个节点,BM9 删除链表的倒数第 n 个节点,BM10 两个链表的第一个公共节点,BM13 判断一个链表是否为回文结构,BM14 链表的奇偶重排>
环:< BM6 判断链表中是否有环, BM7 链表中环的入口点 >
双指针定位倒数节点:< BM8 链表中倒数最后 k 个节点, BM9 删除链表的倒数第 n 个节点 >
反转链表:< BM1 反转链表, BM11 链表相加(二)>
归并排序:< BM5 合并 k 个已排序的链表,BM12 单链表的排序,BM20 数组中的逆序对 >
BM5 合并 k 个已排序的链表
描述
合并 k 个升序的链表并将结果作为一个升序的链表返回其头节点。
F1:归并排序
思路
- 双指针、归并排序、分治
步骤
- 从链表数组的首和尾开始,每次划分从中间开始划分,划分成两半,得到左边 n/2 个链表和右边 n/2 个链表。
- 继续不断递归划分,直到每部分链表数为 1。
- 将划分好的相邻两部分链表,按照两个有序链表合并的方式合并,合并好的两部分继续向上合并,直到最终合并成一个链表。
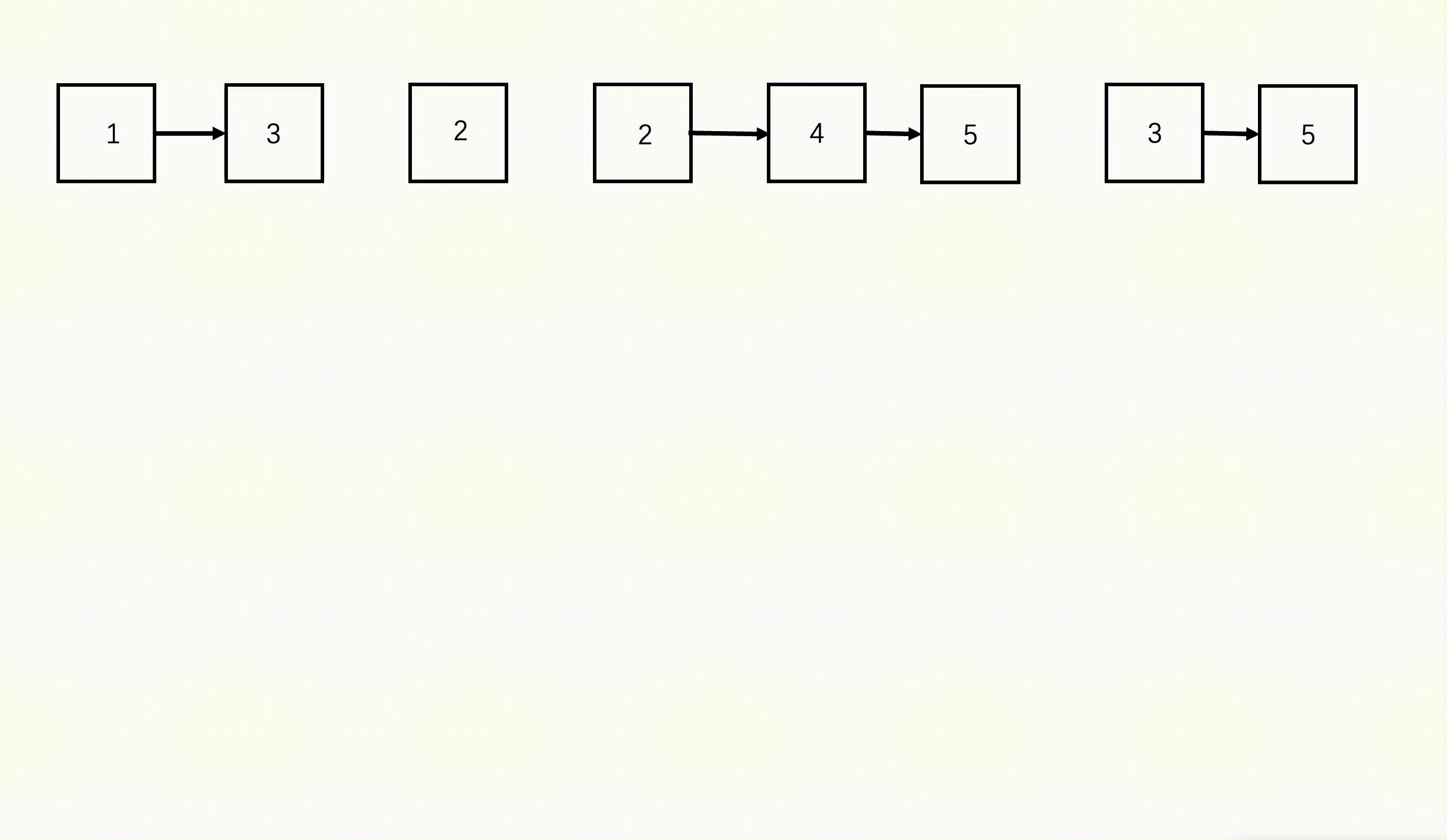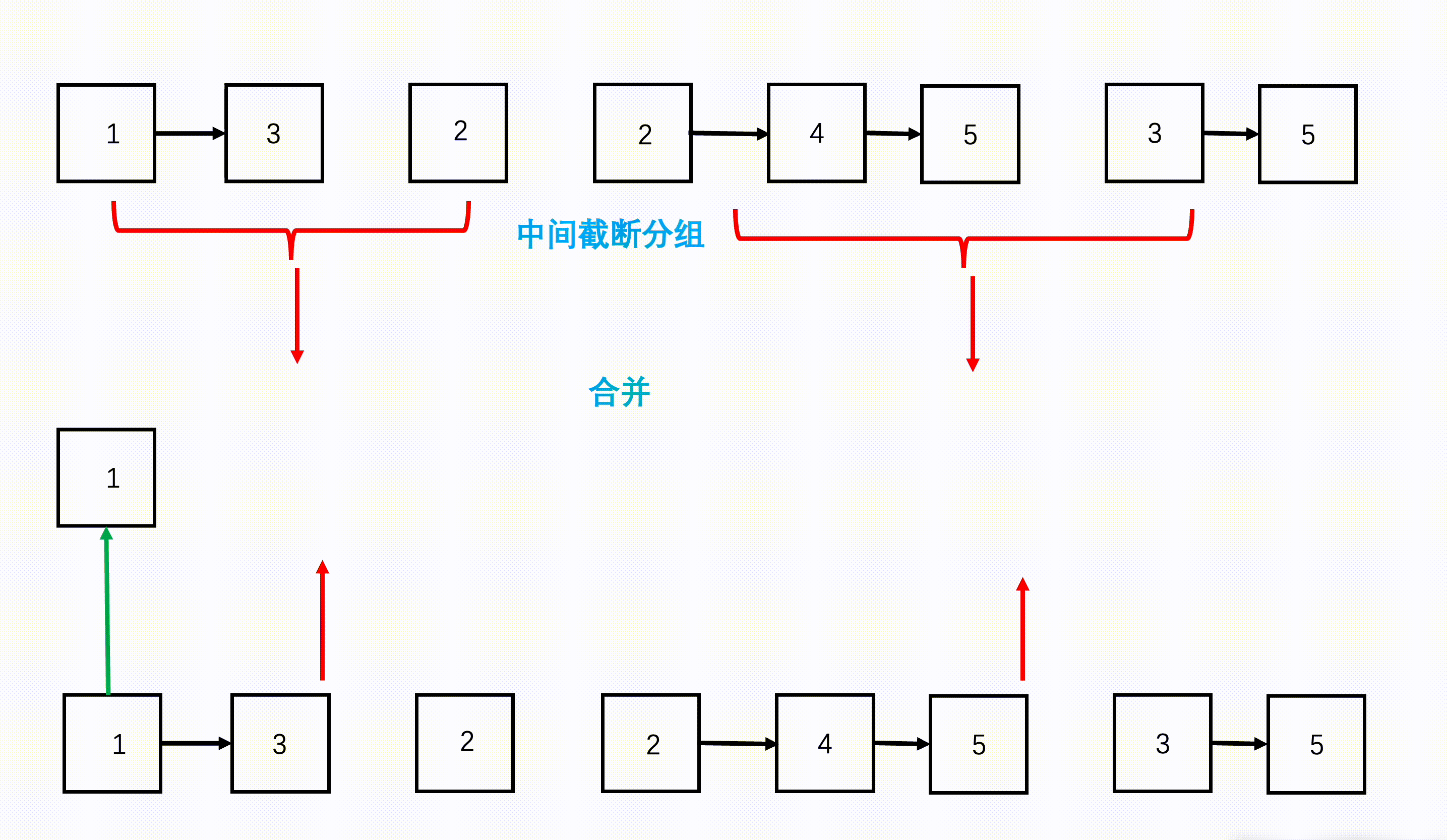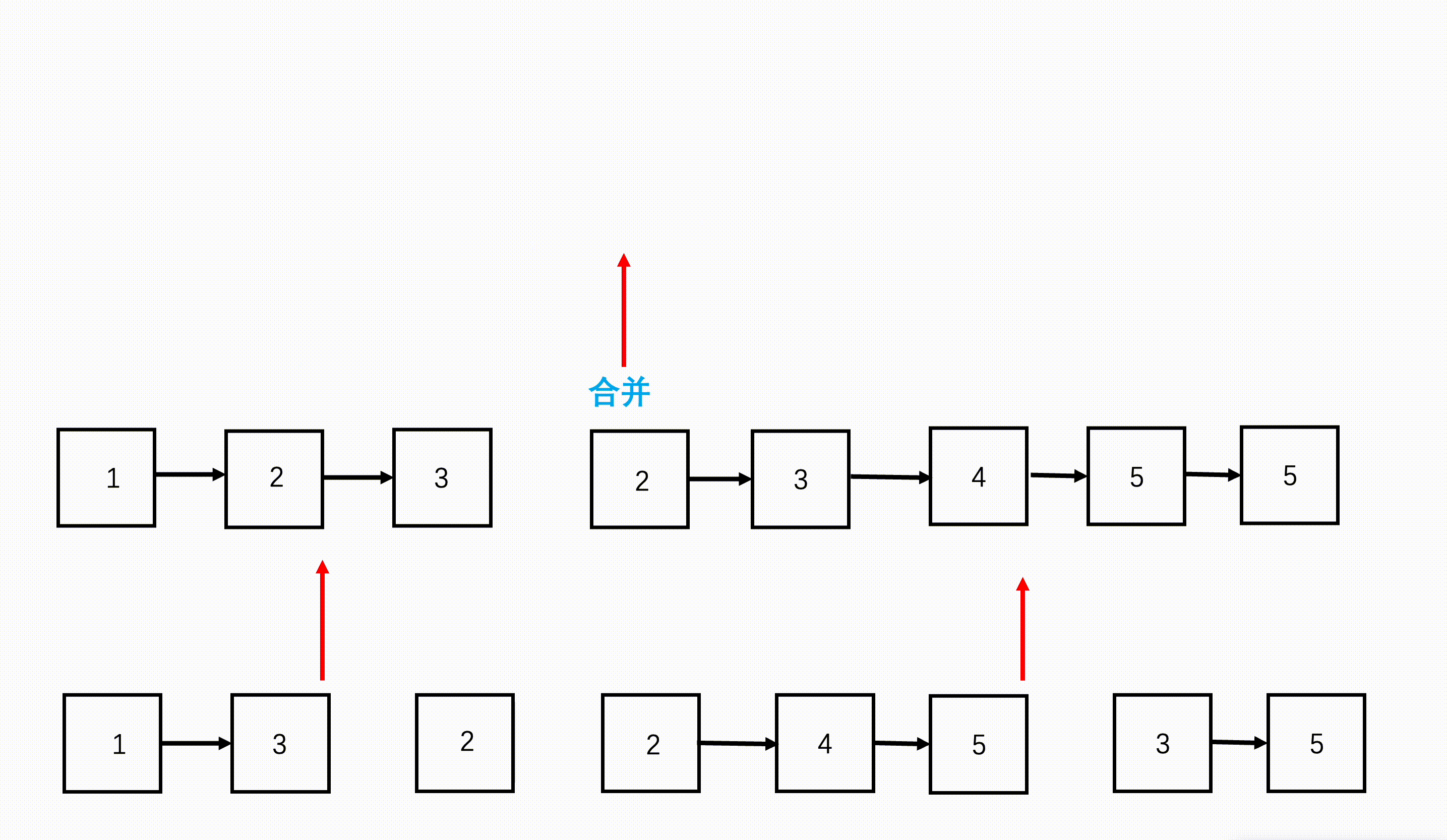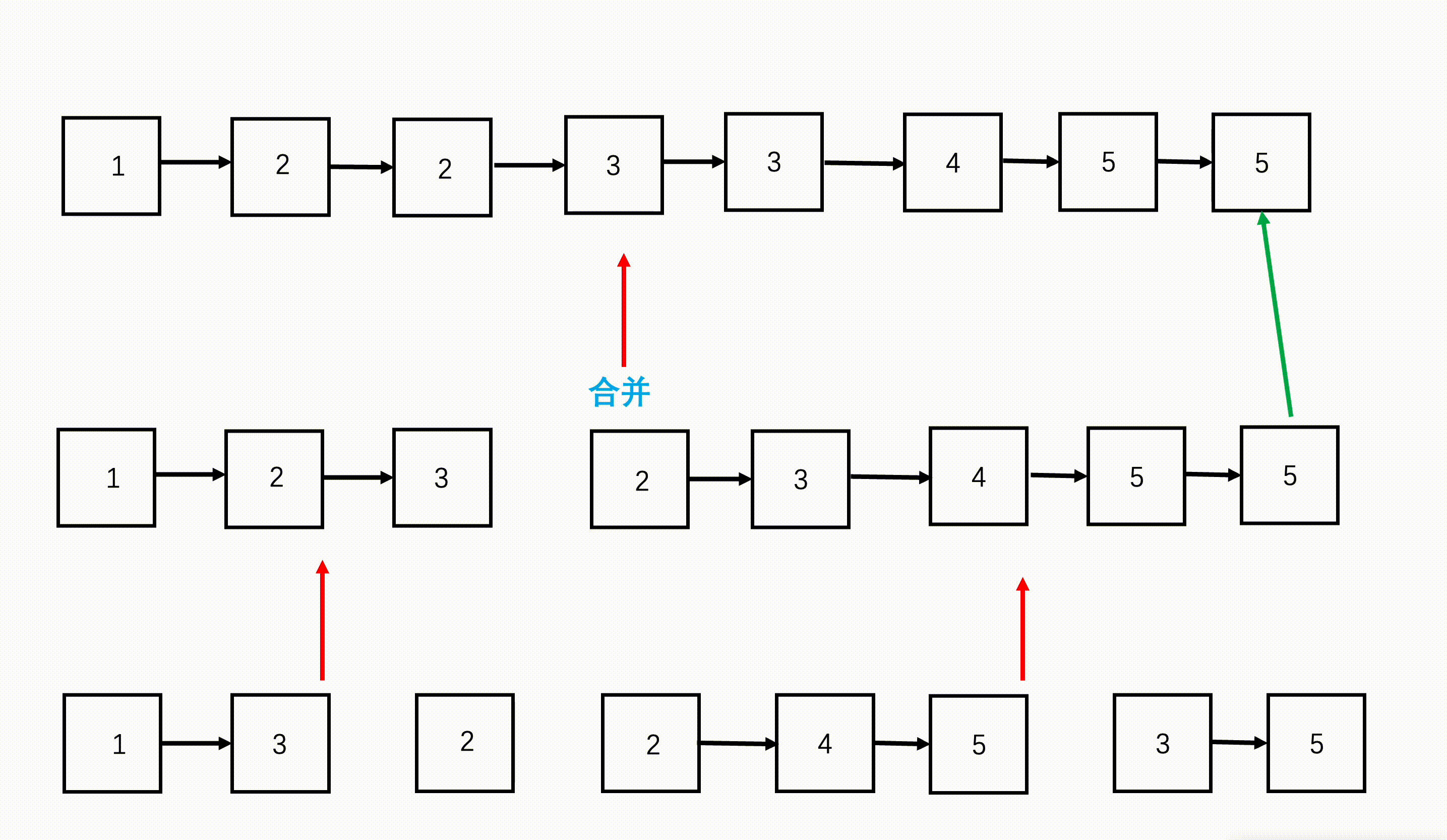
代码
1 | public ListNode mergeKLists(ArrayList<ListNode> lists) { |
时间复杂度
\(O(nlog_2k)\)
n 为所有链表总节点数,分治为二叉树型递归,最坏情况下二叉树每层合并都是 \(O(n)\) 个节点,因为分治一共有 \(O(log_2k)\) 层。
空间复杂度
\(O(log_2k)\)
最坏情况下递归 \(log_2k\) 层,需要 \(log_2k\) 的递归栈。
F2:优先级队列
思路
不同于方法 1,该方法直接使用 k 个指针,每次比较得出 k 个数字中的最小值。
每次优先级队列中有 k 个元素,可以直接拿出最小的元素,再插入下一个元素,相当于每次都是链表的 k 个指针在比较大小,只移动最小元素的指针。
步骤
- 构造一个小根堆(优先级队列);
- 先遍历 k 个链表头,将不是空节点的节点加入小根堆;
- 每次依次弹出小根堆中的最小元素,将其连接在合并后的链表后面,然后将这个节点的原链表中的后序节点(不为空的话)加入队列,与方法 1 归并排序双指针的过程类似。
代码
1 | public ListNode mergeKLists(ArrayList<ListNode> lists) { |
时间复杂度
\(O(nlog_2k)\)
n 为所有链表总节点数,最坏要遍历所有节点,每次加入优先级队列排序需要 \(O(log_2k)\)
空间复杂度
\(O(k)\)
优先队列的大小不会超过 k
BM6 判断链表中是否有环
描述
判断给定的链表中是否有环。如果有环则返回 true,否则返回 false。
F1:双指针
思路
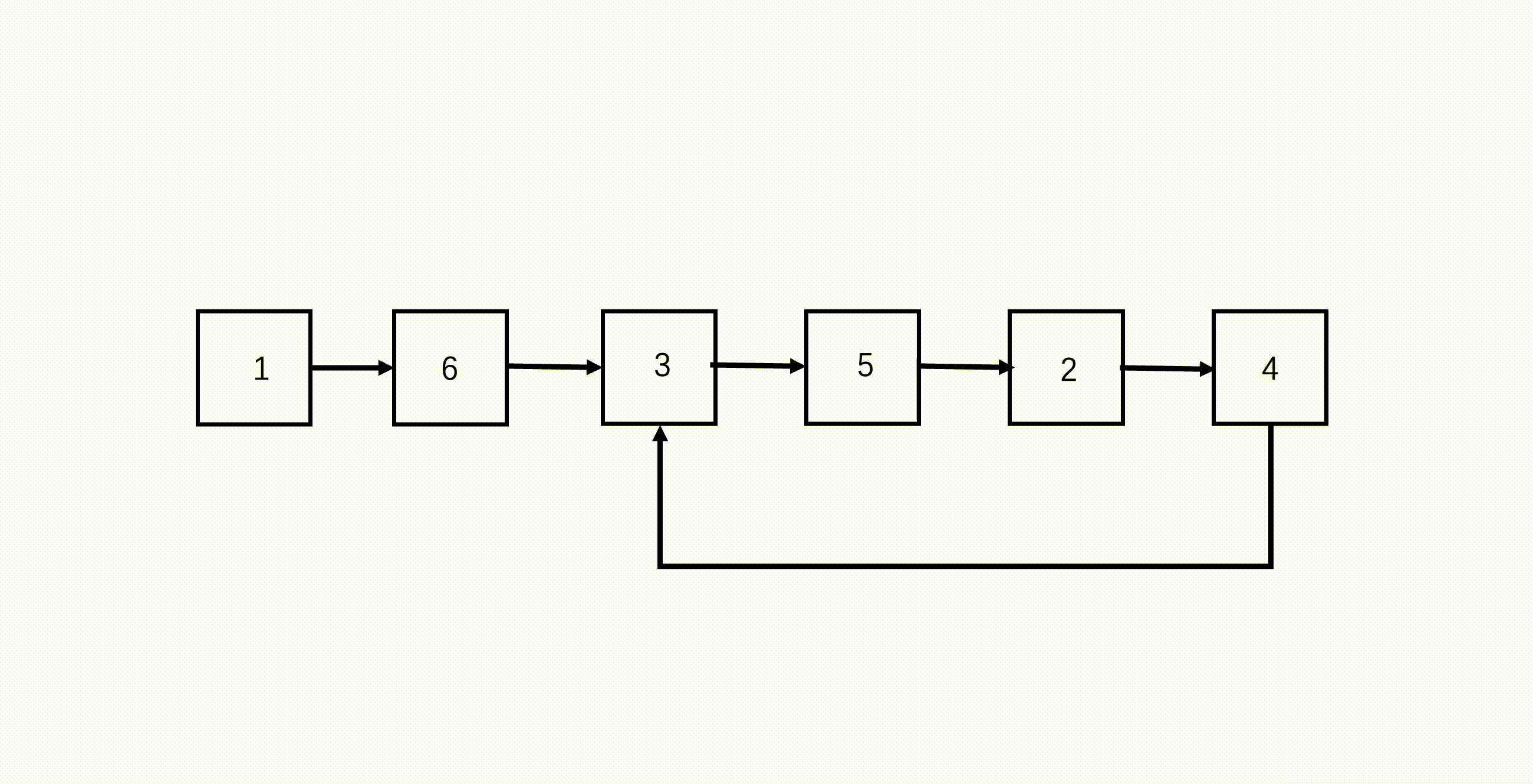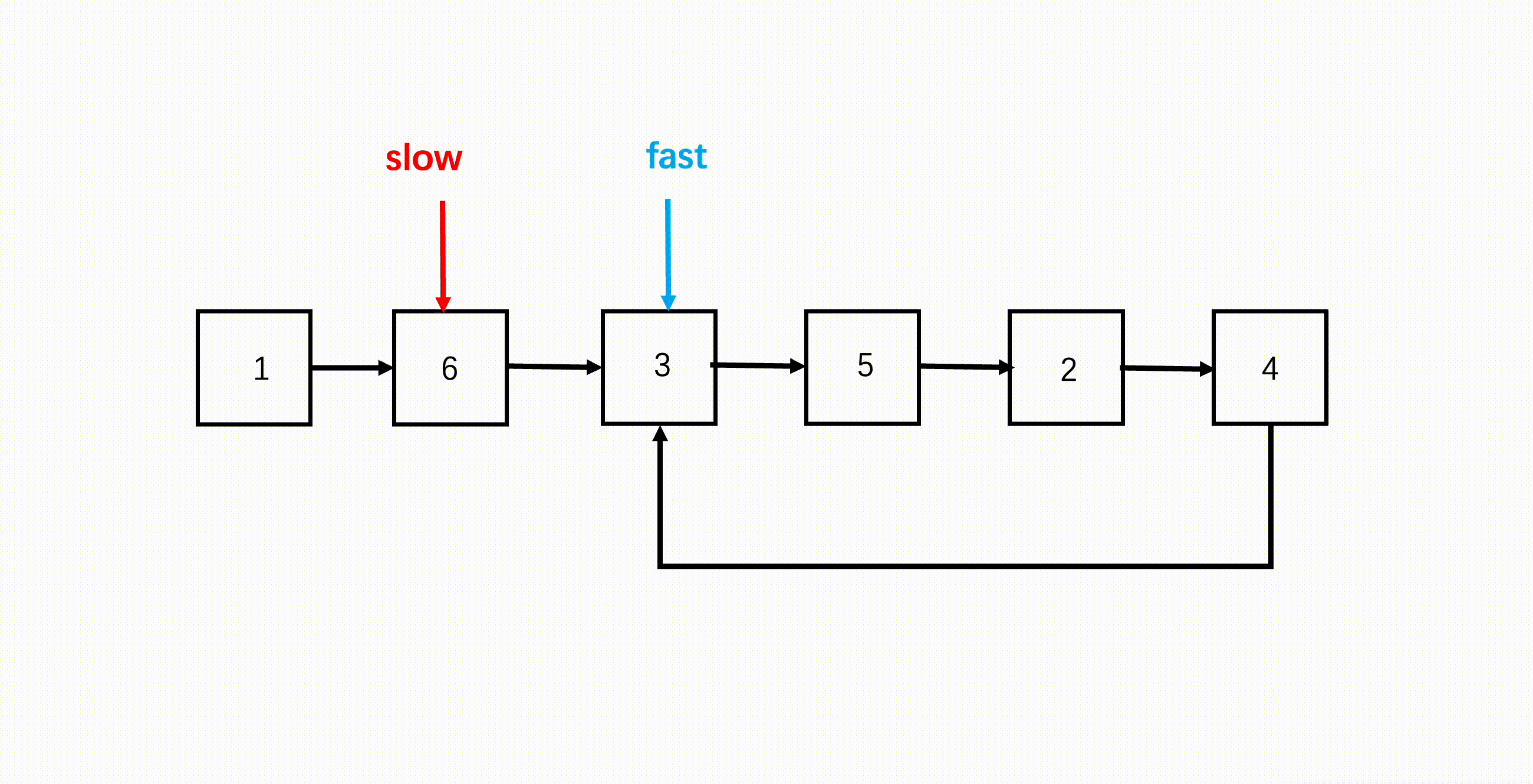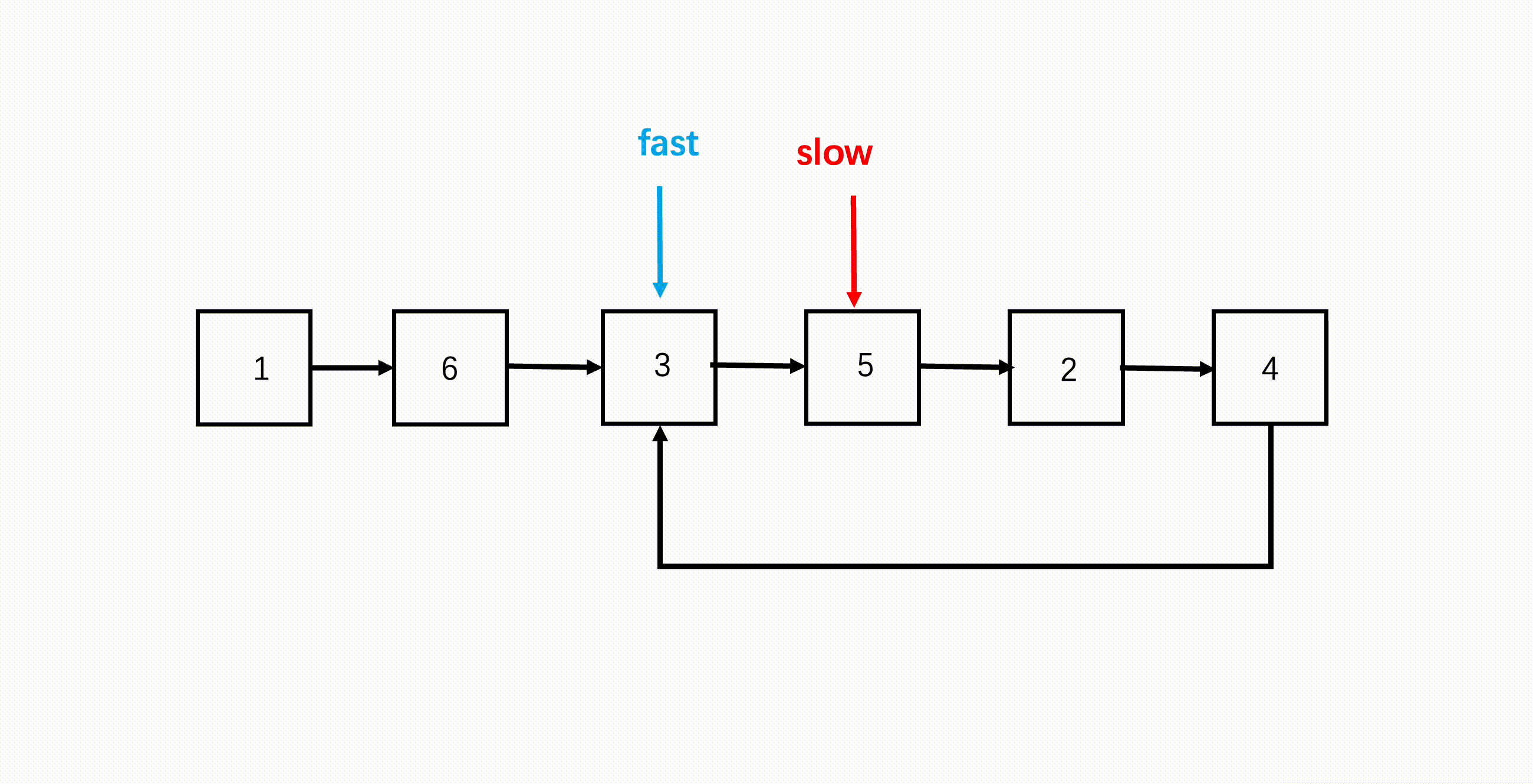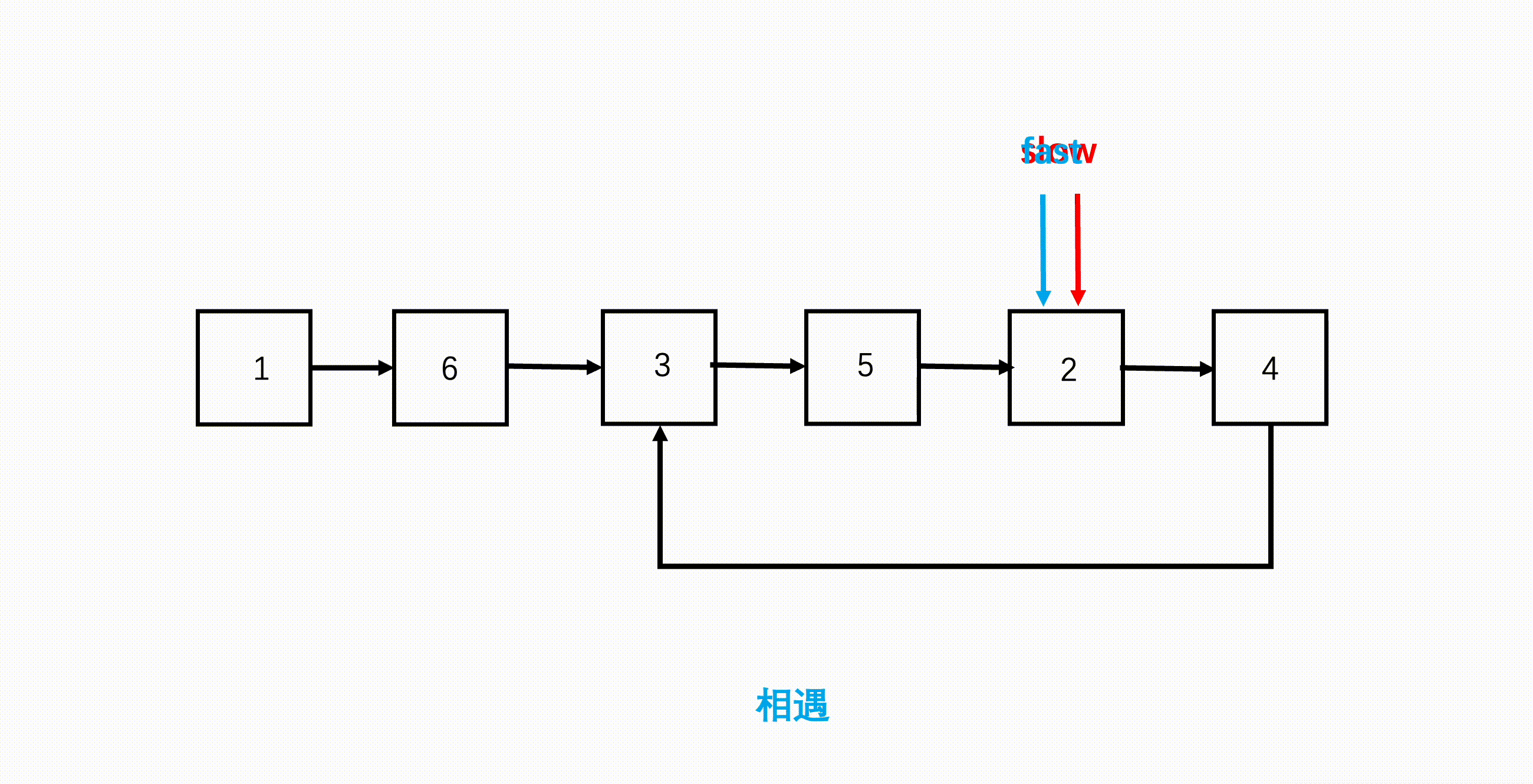
线性与环形链表特点:
线性链表末尾一定有 null。
环形链表的环一定在末尾,末尾没有 null 了。
线性与环形链表结束条件:
线性链表的结束条件就是遍历到 null。
环形链表会不断循环,需要借助双指针才能结束。同向访问的双指针,因为速度不同,只要有环,二者一定能相遇。
步骤
- 设置快慢两指针,初始都指向链表头;
- 遍历链表,快指针每次走两步,慢指针每次走一步;
- 如果快指针到了链表末尾,说明没有环,因为它每次走两步,所以要验证连续两步是否为 null;
- 如果链表有环,那快慢双指针会在环内循环,因为快指针每次走两步,因此快指针会在环内追到慢指针,二者相遇就代表有环。
代码
1 | public boolean hasCycle(ListNode head) { |
时间复杂度
\(O(M)\)
最坏情况下遍历链表 n 个节点。
空间复杂度
\(O(1)\)
仅使用了两个指针,没有额外辅助空间。
BM7 链表中环的入口点
描述
给一个长度为 n 链表,若其中包含环,请找出该链表的环的入口结点,否则,返回 null。
分解任务
- 判断链表是否有环;
- 在有环的链表中找到环的入口。
F1:双指针
思路
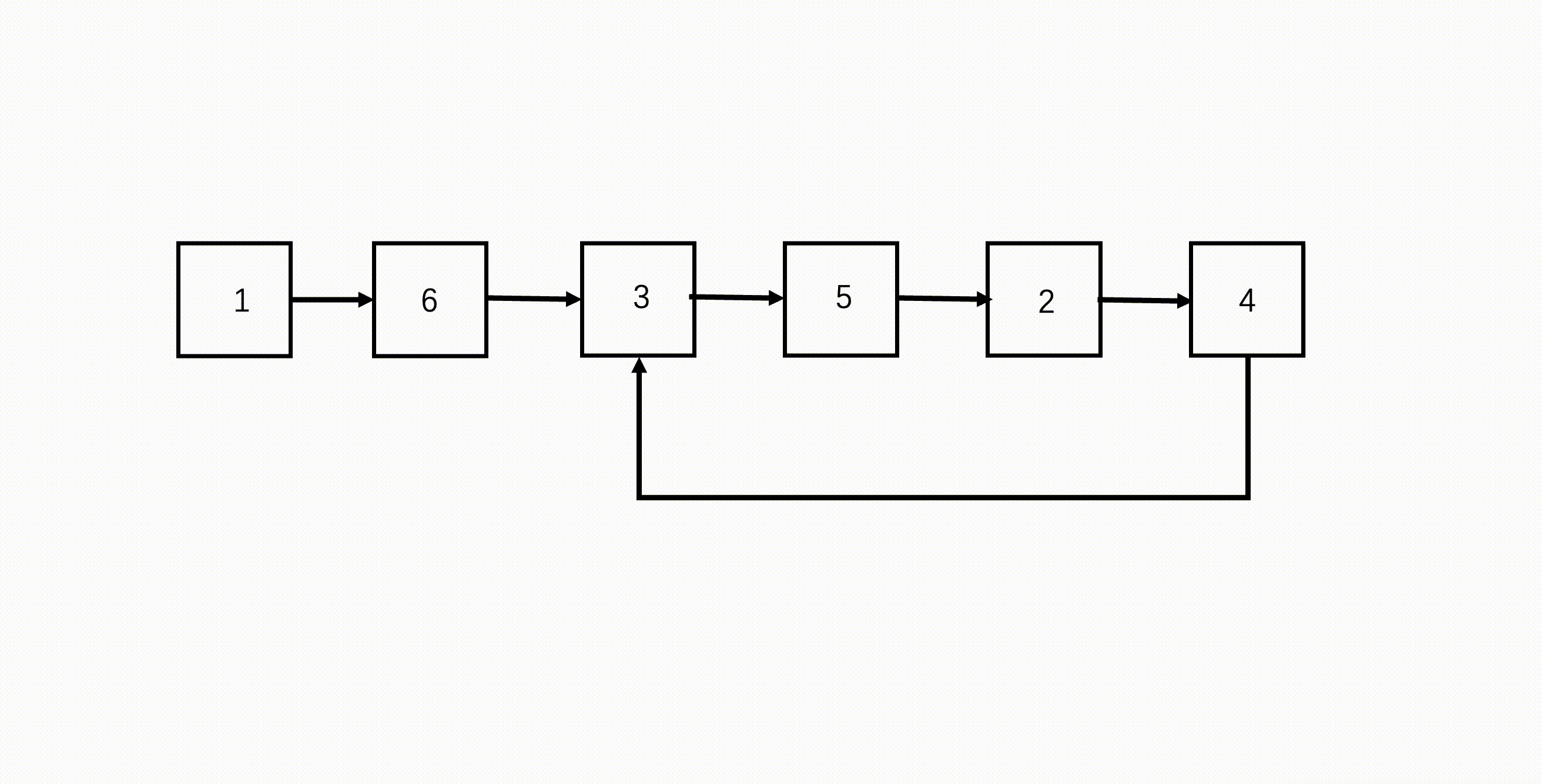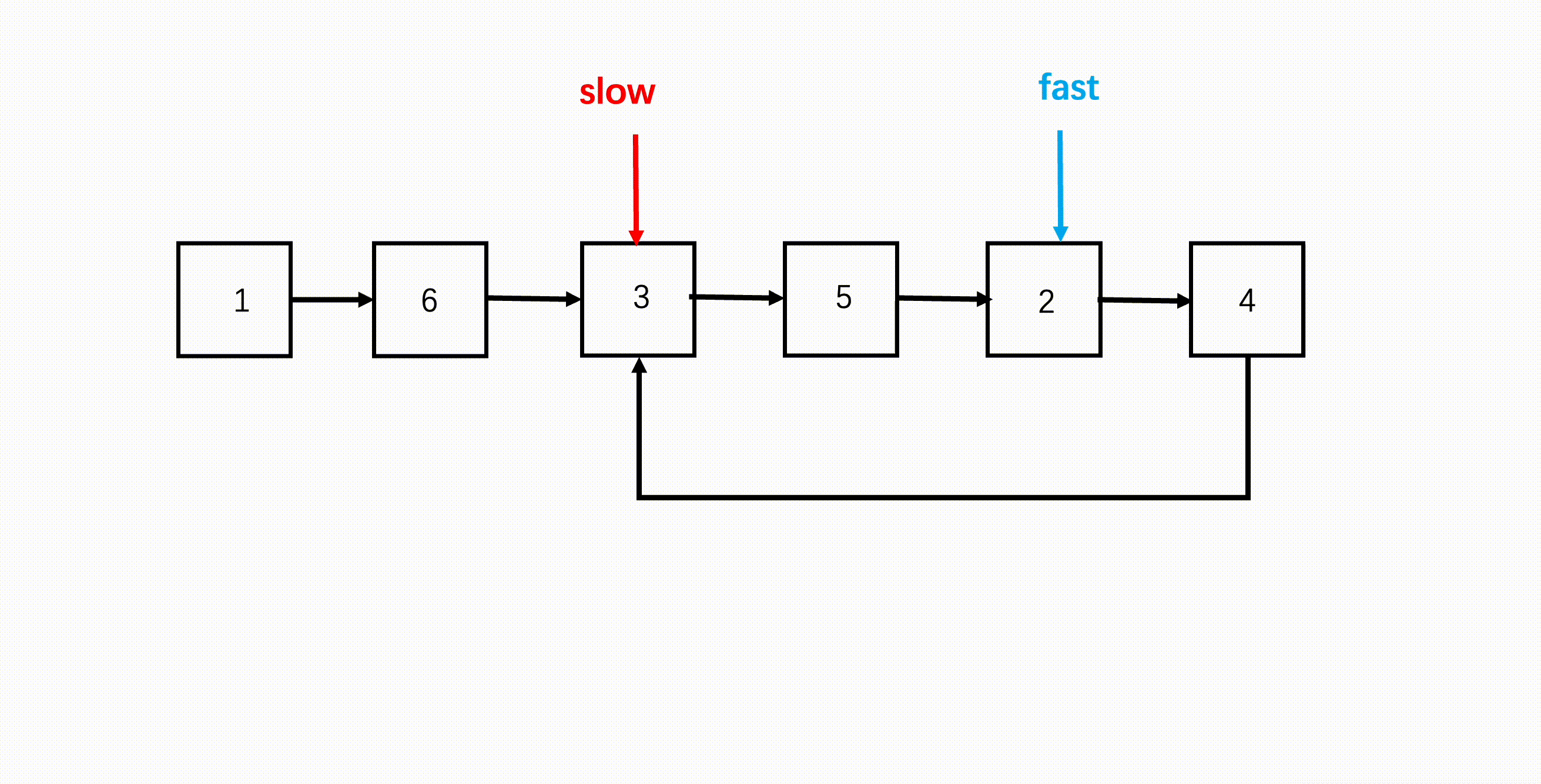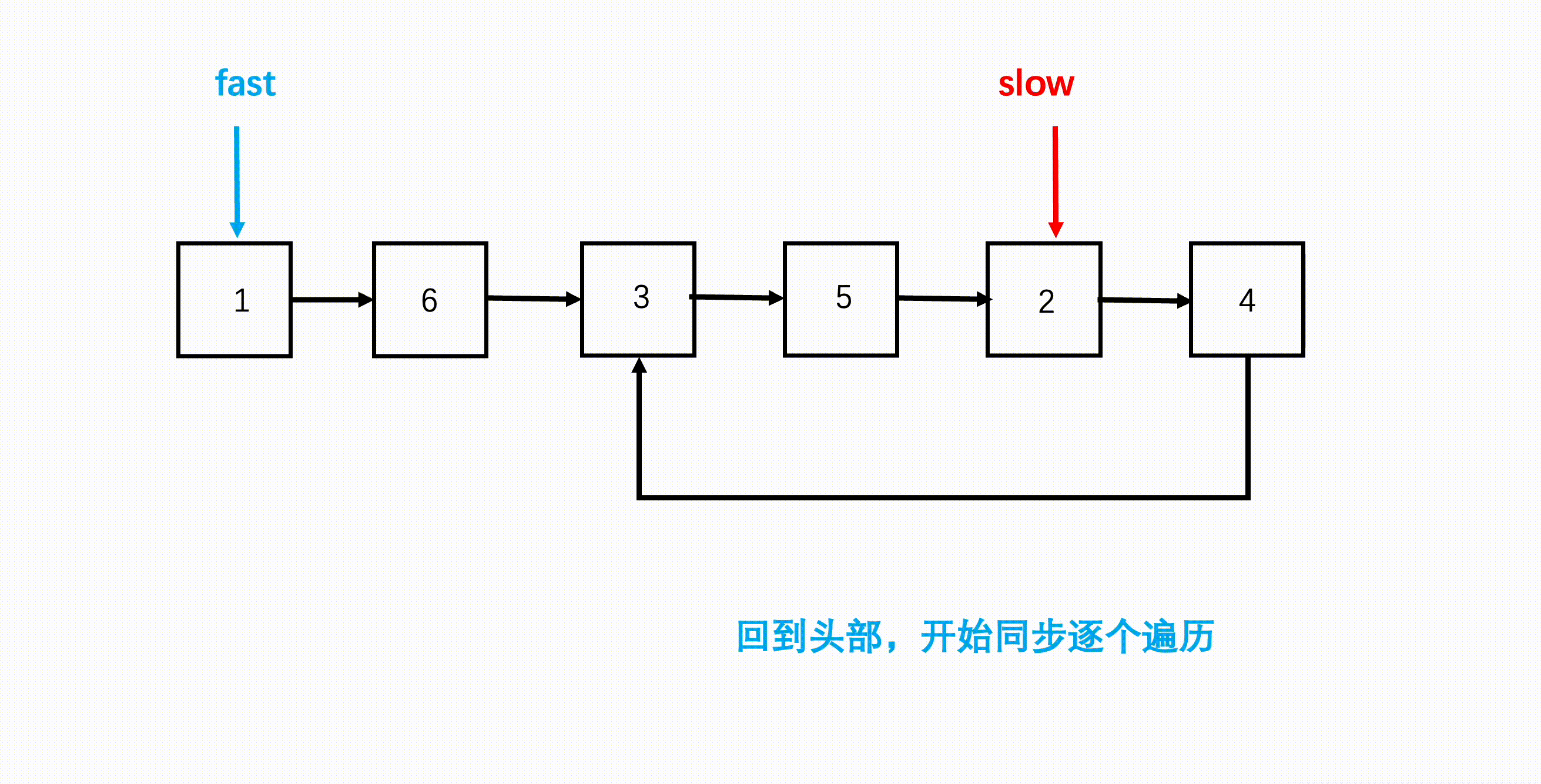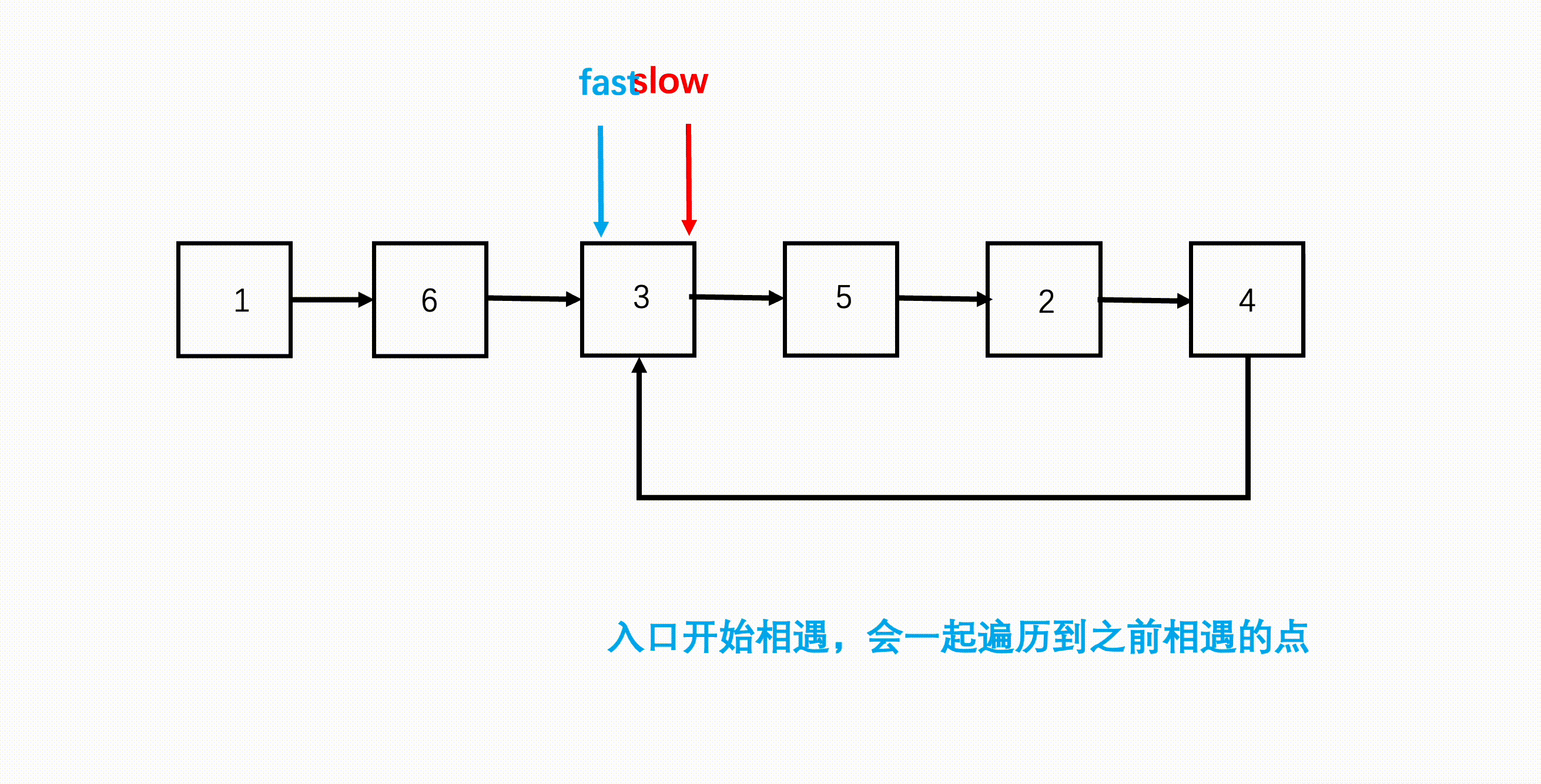
如何找到环的入口?
一个有环链表。
假设快指针在环中走了 \(n\) 圈,慢指针走了 \(m\) 圈,两者相遇。
链表头节点到环入口点距离为 \(x\),环入口到相遇点距离为 \(y\),相遇点到环入口点距离为 \(z\)。
快指针一共走了 \(x + n(y + z) + y\) 步,慢指针一共走了 \(x + m(y + z) + y\) 步。
快指针走的步数是慢指针的两倍,则 \[ x + n(y + z) + y = 2(x + m(y + z) + y) \] 进一步推导, \[ x+y=(n-2m)(y+z) \] 因为环的大小是 \(y+z\),说明从链表头经过环入口到达相遇地方经过的距离等于整数倍环的大小。那么,我们从头开始遍历到相遇位置,和从相遇位置开始在环中遍历,会使用相同的步数,而双方最后都会经过入口到相遇位置这 \(y\) 个节点,说明这 \(y\) 个节点它们就是重叠遍历的,那它们从入口位置就相遇了,这样就找到了入口节点。
步骤
- 使用 BM6 方法判断链表是否有环,并找到相遇节点。
- 慢指针继续在相遇节点,快指针回到链表头,两个指针同步逐个元素开始遍历链表。
- 两者再次相遇的地方就是环的入口。
代码
1 | // 寻找链表中环的入口节点 |
时间复杂度
\(O(n)\)
最坏情况下遍历链表两次
空间复杂度
\(O(1)\)
使用了常数个指针,没有额外辅助空间
BM8 链表中倒数最后 k 个节点
描述
输入一个长度为 n 的链表,设链表中的元素的值为 ai ,返回该链表中倒数第 k 个节点。
如果该链表长度小于 k,请返回一个长度为 0 的链表。
F1:双指针(推荐)
思路
链表无法逆序遍历。
如果当前我们处于倒数第 k 的位置上,即距离链表尾的距离是 k。
我们假设双指针指向这两个位置,二者同步向前移动,当前面快指针到了链表尾的时候,两个指针之间的距离还是 k。
虽然无法让指针逆向移动,但是上述思路却可以正向实施。
步骤
- 准备一个快指针,从链表头开始,在链表上先走 k 步。
- 准备慢指针指向原始链表头,代表当前节点,快慢指针之间的距离一直都是 k。
- 快慢指针同步移动,当快指针到达链表尾部的时候,慢指针正好到了倒数 k 个节点的位置。
代码
1 | public ListNode FindKthToTail(ListNode pHead, int k) { |
时间复杂度
\(O(n)\)
总共遍历 n 个链表节点
空间复杂度
\(O(1)\)
常数级指针变量,无额外辅助空间使用
F2:先找长度再找最后 k
思路
链表不能逆向遍历,也不能直接访问。但是对于倒数第 k 个位置,我们只需知道是正数多少位,还是可以直接遍历得到的。
步骤
- 遍历链表,找到链表的长度;
- 如果链表长度小于 k,返回空节点。
- 如果链表长度够长,我们从头节点往后遍历 n - k 次即可。
代码
1 | public ListNode FindKthToTail(ListNode pHead, int k) { |
时间复杂度
\(O(n)\)
最坏情况下,两次遍历 n 个链表元素
空间复杂度
\(O(1)\)
常数级指针变量,无额外辅助空间使用
BM9 删除链表的倒数第 n 个节点
描述
给定一个链表,删除链表的倒数第 n 个节点并返回链表的头指针
例如,给出的链表为: 1 -> 2 -> 3 -> 4 -> 5, n = 2。删除了链表的倒数第 n 个节点,链表变为 1 -> 2 -> 3 -> 5。
备注:题目保证 n 一定是有效的。
F1:三指针
思路
思路与 BM8 链表中倒数最后 k 个节点的思路基本一致,不同的是,在其基础上增加一个哨兵表头以及一个指针。
步骤
- 给链表添加一个表头,处理删掉第一个元素时比较方便。
- 准备一个快指针,在链表上先走 n 步。
- 准备一个慢指针指向原始链表头,一个前序指针指向添加的表头。快慢指针之间的距离一直都是 n,前序指针始终指向慢指针的前序节点。
- 三指针同步向前移动,当快指针到达链表尾部 null 的时候,慢指针正好到了倒数第 n 个节点。
- 将前序指针指向的前序节点的指针指向慢指针后一个节点,删除掉慢指针指向的节点。
代码
1 | public ListNode removeNthFromEnd(ListNode head, int n) { |
时间复杂度
\(O(n)\)
最坏情况下,遍历 n 个链表节点。
空间复杂度
\(O(1)\)
常数级指针变量,无额外辅助空间使用
BM10 两个链表的第一个公共节点
描述
输入两个无环的单向链表,找出它们的第一个公共结点,如果没有公共节点则返回空。
F1:双指针
思路
使用两个指针 p1,p2,一个从链表 1 的头节点开始遍历,一个从链表 2 的头节点开始遍历。
p1、p2 一起遍历,若 p1 先走到链表 1 的尽头(null),则从链表 2 的头节点继续遍历。同样的,如果 p2 先走到链表 2 的尽头(null),则从链表 1 的头节点继续遍历,也就是说,p1 和 p2 都会遍历链表 1 和链表 2.
两个指针,同样的速度,走完同样的长度(链表 1 + 链表 2),不管两条链表有无相同节点,都能够同时到达终点。
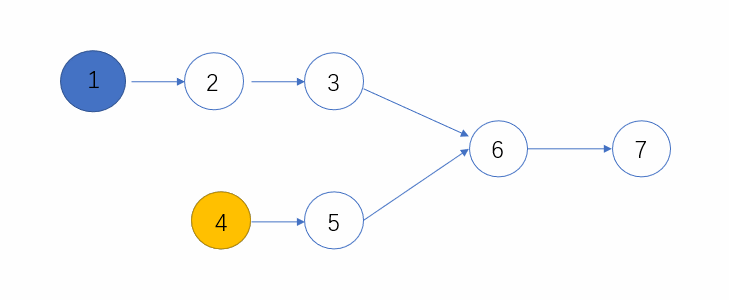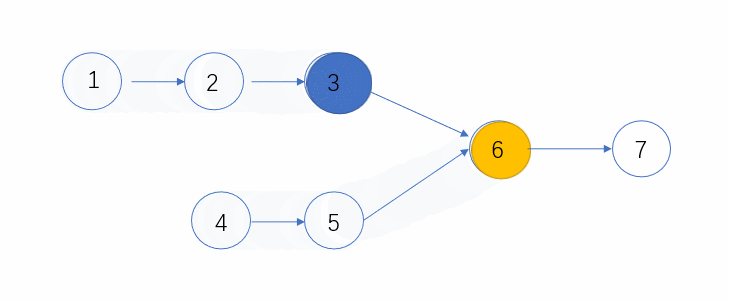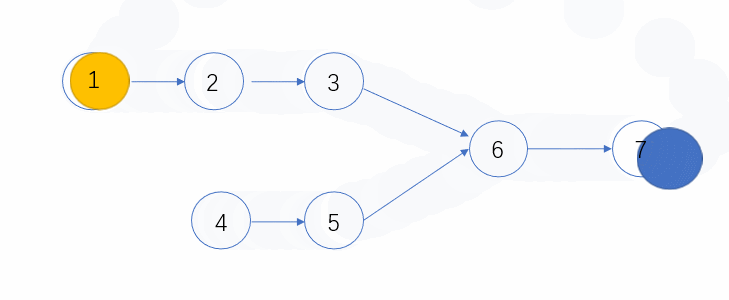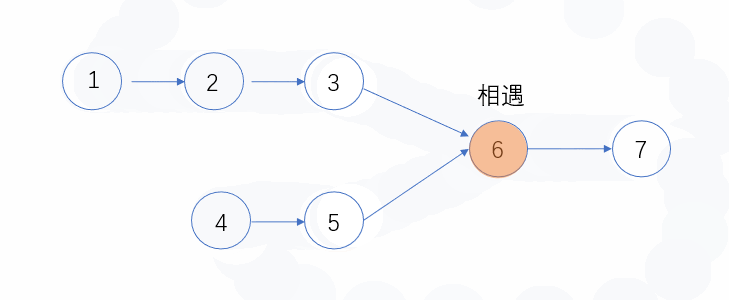
因此,如何确定公共节点:
- 有公共节点的时候,p1 和 p2 必会相遇,因为长度一样,速度也一样,必会走到相同的地方。两者相遇的节点就是第一个公共的节点。
- 无公共节点的时候,此时 p1 和 p2 都会走到终点,那么他们此时都是 null,也算相等。
代码
1 | public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) { |
时间复杂度
\(O(m+n)\)
链表 1 和链表 2 的长度之和。
空间复杂度
\(O(1)\)
常数级指针变量,无额外辅助空间使用。
BM13 判断一个链表是否为回文结构
描述
给定一个链表,请判断该链表是否为回文结构。
回文是指该字符串正序逆序完全一致。
F1:栈逆序
步骤
- 遍历链表,将链表元素依次加入栈中。
- 依次从栈中弹出元素,和链表的顺序遍历比较,如果都是相同的,那么就是回文,否则就不是。
代码
1 | public boolean isPail (ListNode head) { |
时间复杂度
\(O(n)\)
n 为链表长度,遍历链表入栈为 \(O(n)\),后续再次遍历链表和栈。
空间复杂度
\(O(n)\)
记录链表元素的辅助栈长度和链表相同。
F2: 双指针寻中逆序
步骤
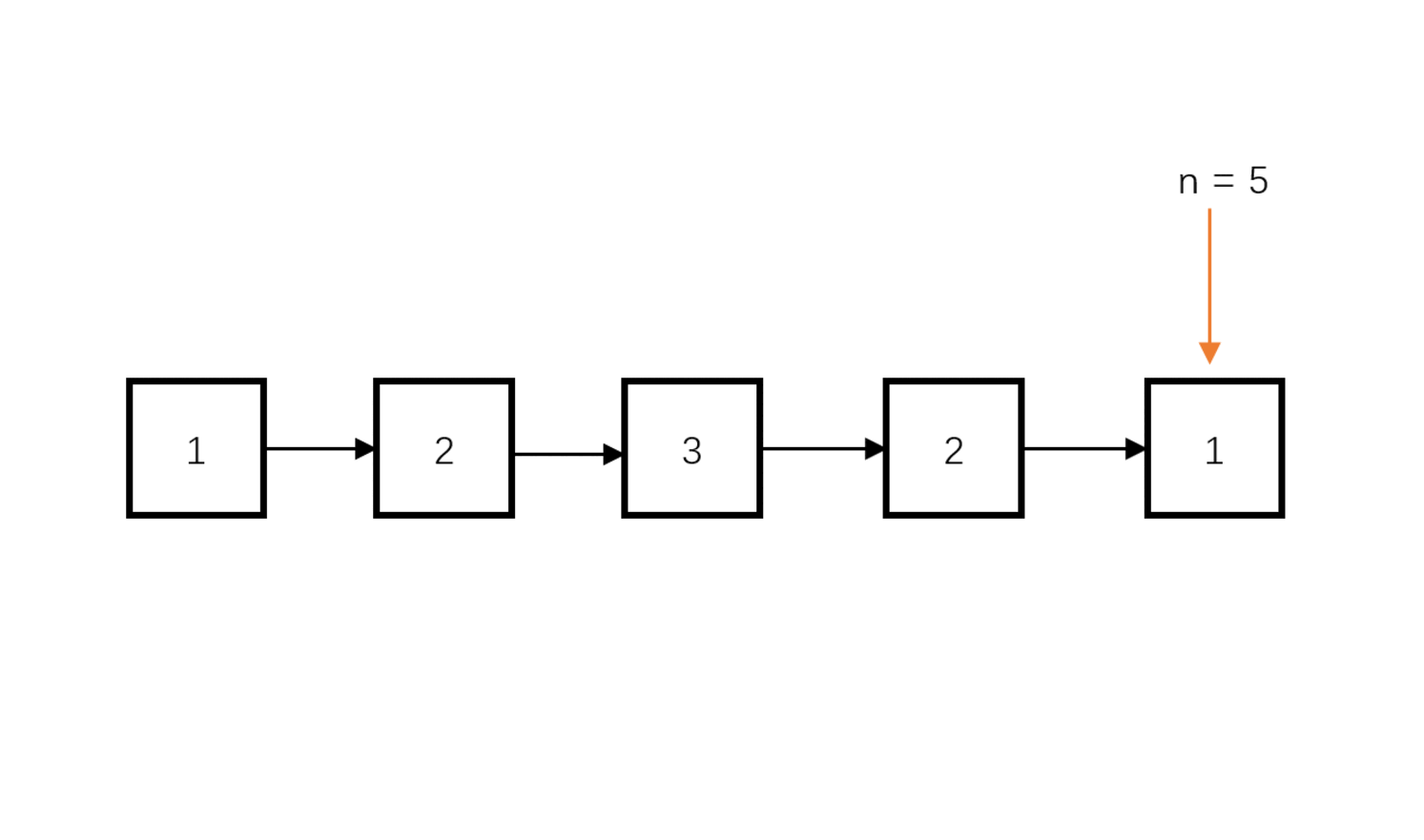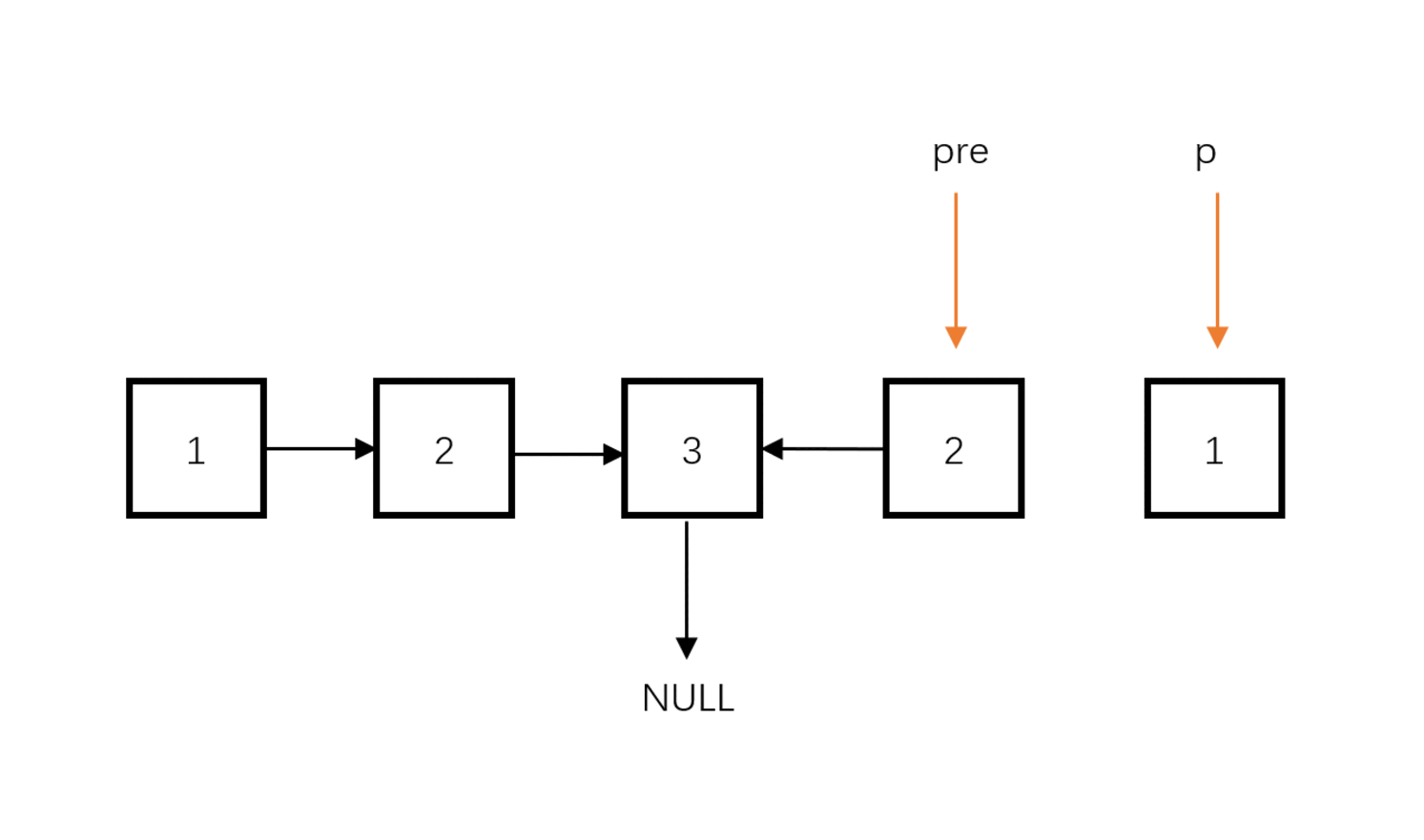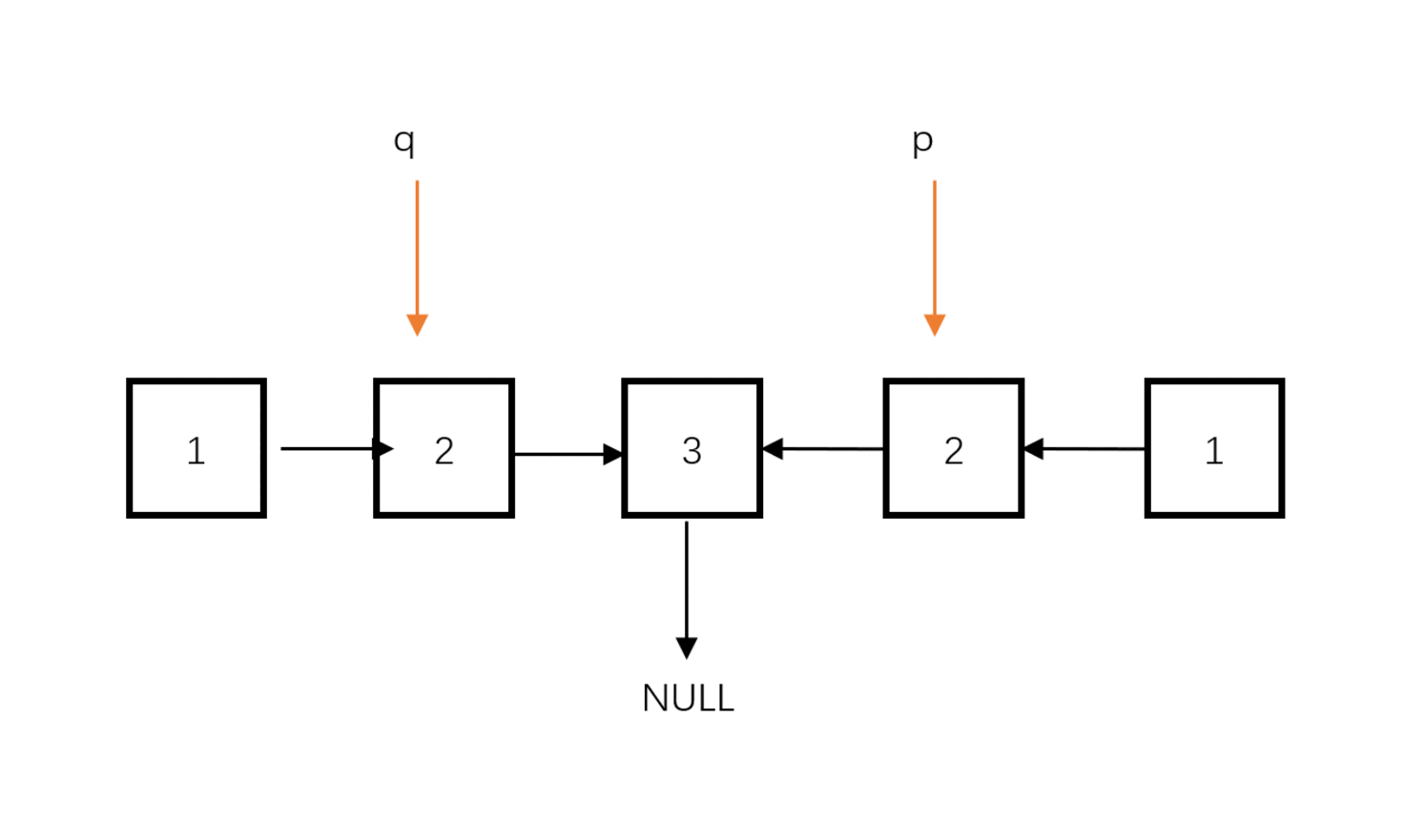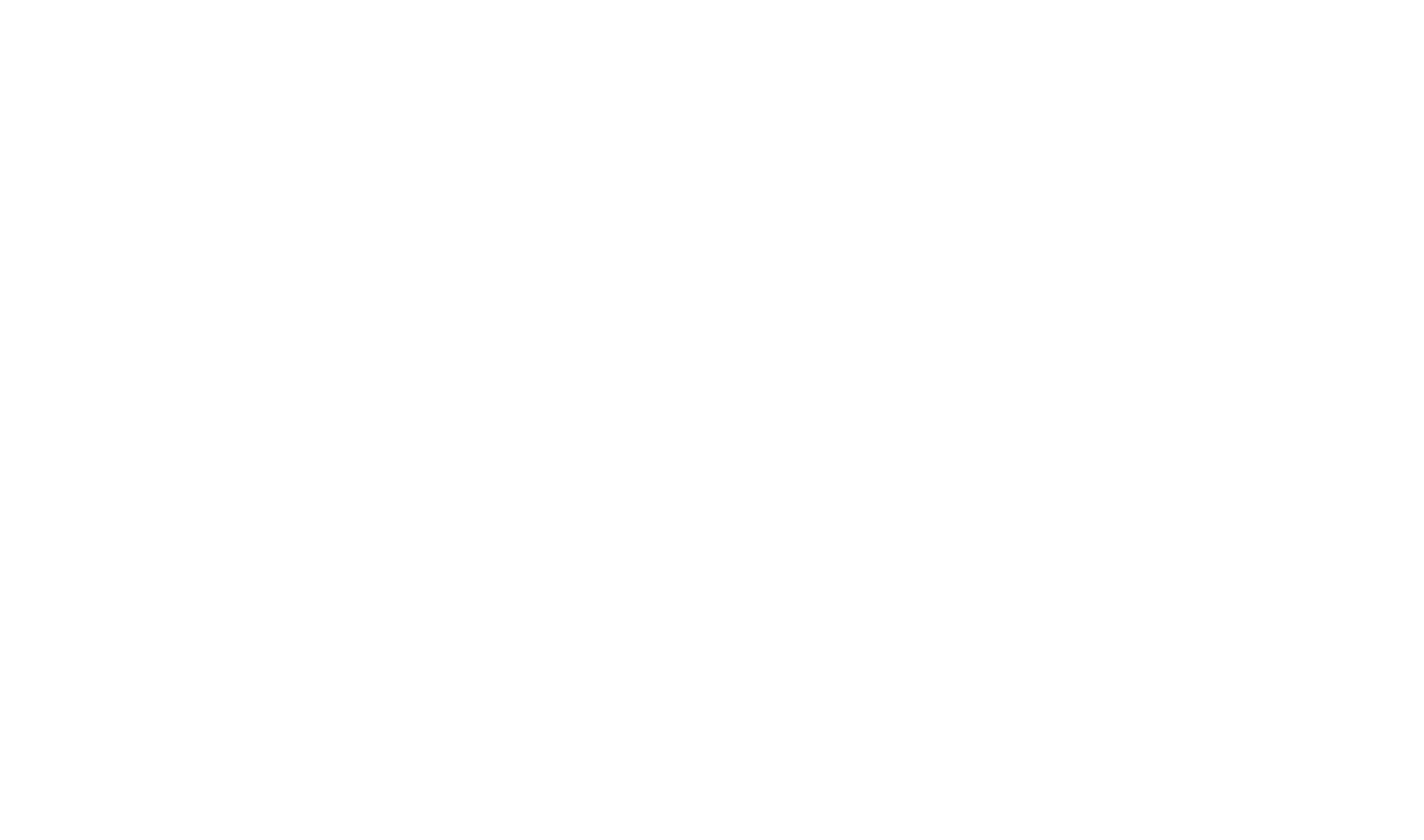
- 慢指针每次走一个节点,快指针每次走两个节点,快指针到达链表终点(null)时,慢指针刚好到了链表中点。
- 从中点位置开始,将后半段链表反转。
- 双指针左指针指向头节点,右指针指向反转后的头节点(原链表的尾节点),都向中间遍历,依次比较对应位置的节点值是否相等。
快慢指针寻找中点:
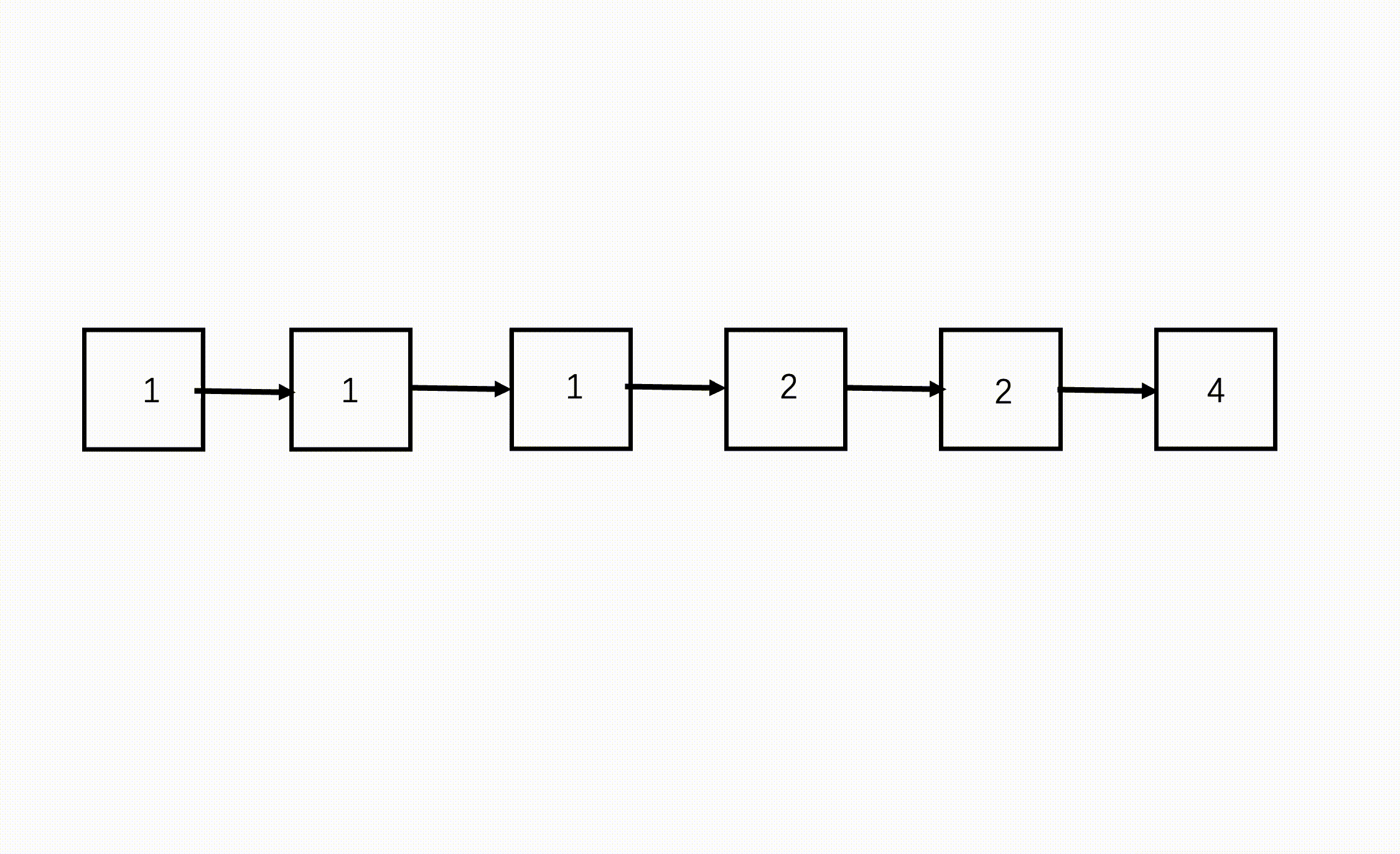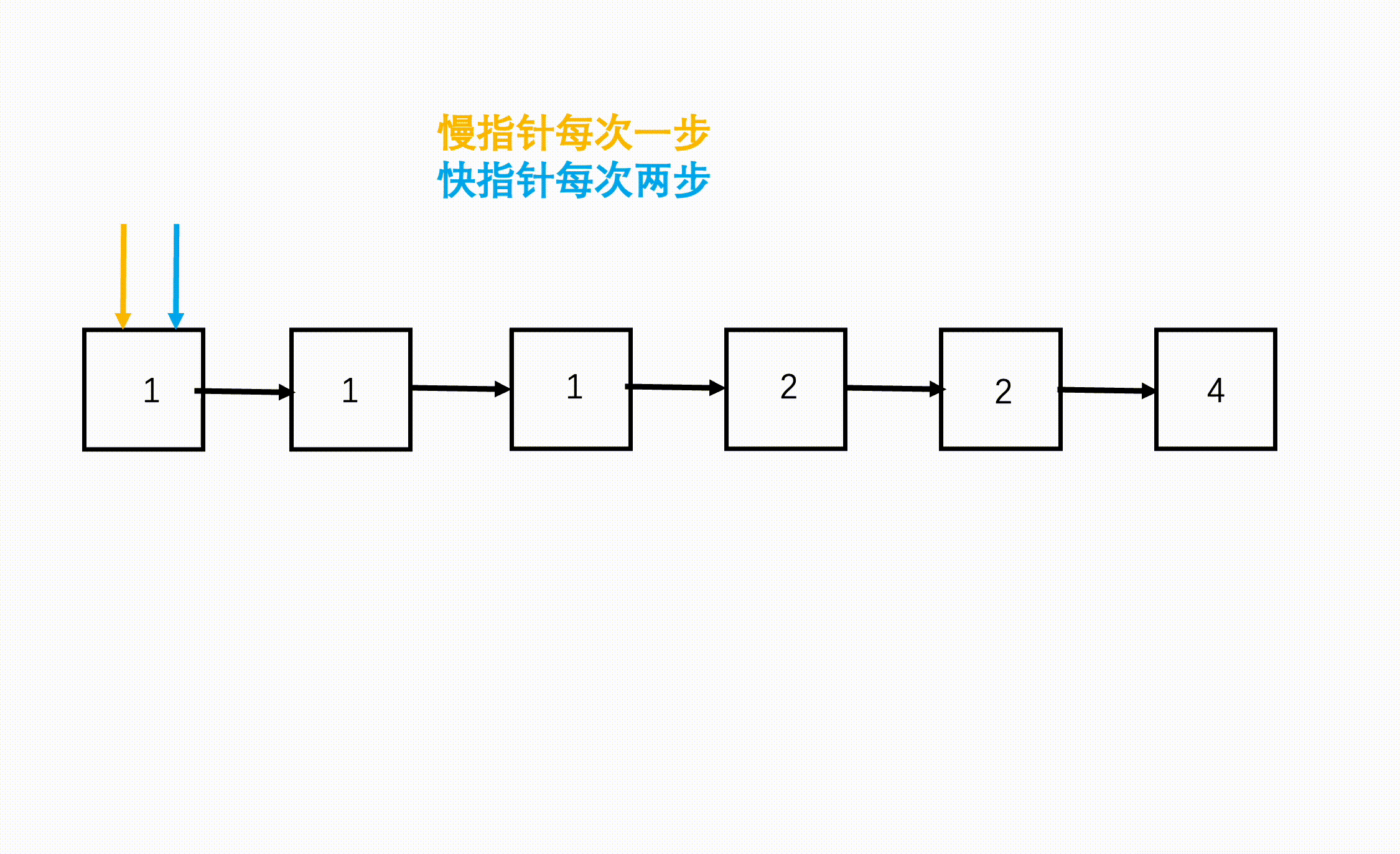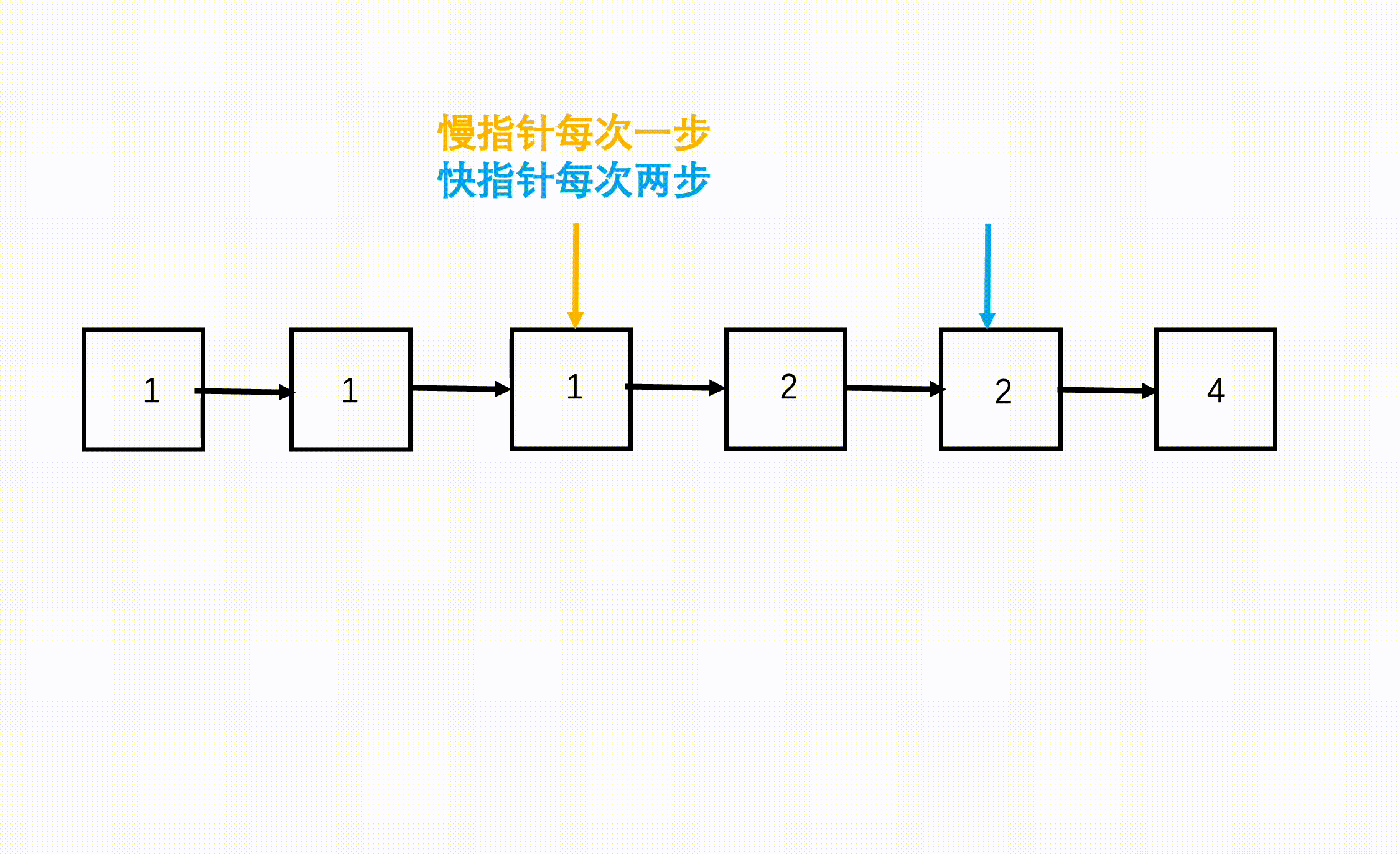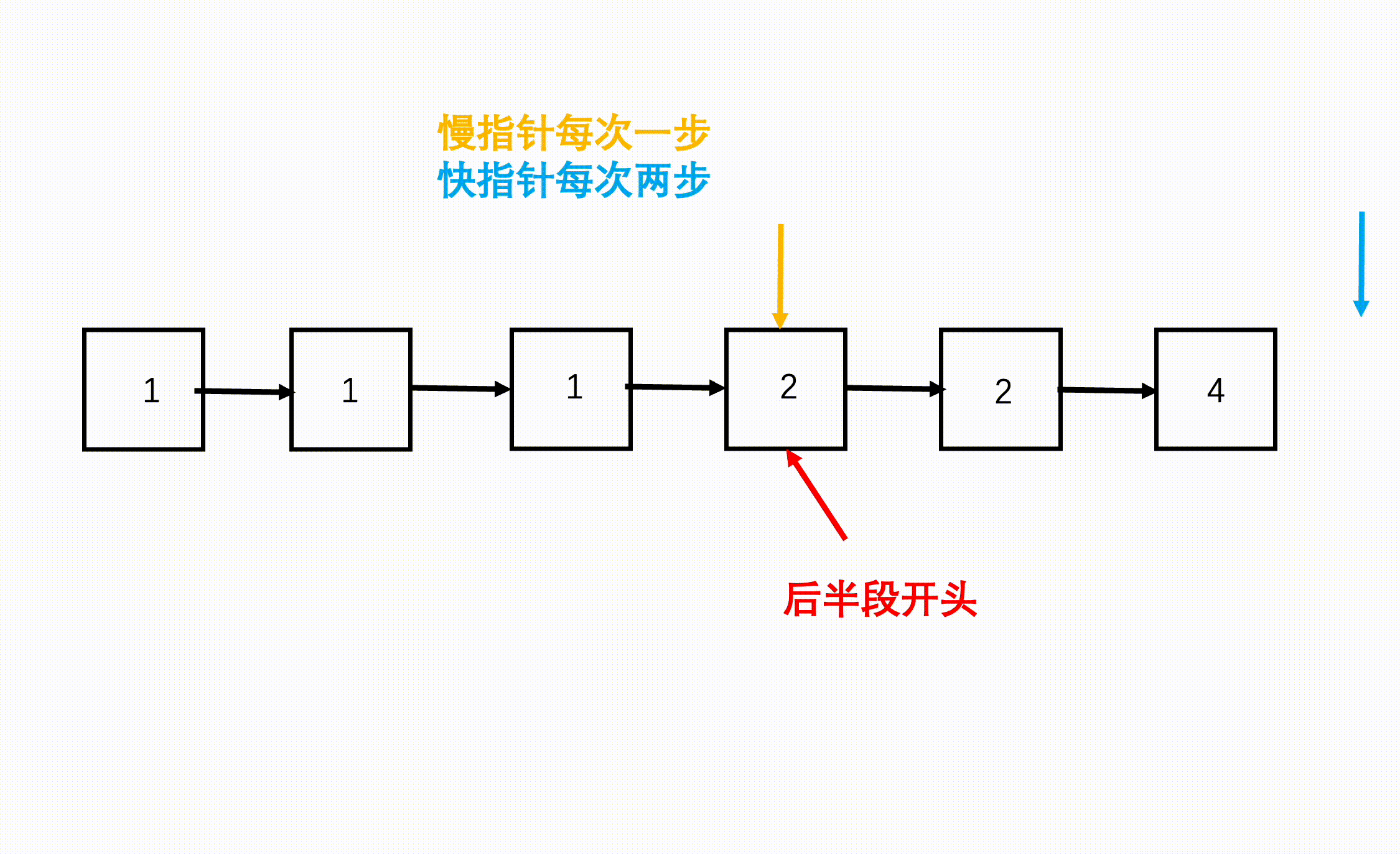
链表反转及比较:
代码
1 | public boolean isPail(ListNode head) { |
时间复杂度
\(O(n)\)
n 为链表长度,双指针找到中点遍历半个链表,后续反转链表为 \(O(n)\),然后再遍历两份半个链表。
空间复杂度
\(O(1)\)
常数级指针变量,没有额外辅助空间。
BM14 链表的奇偶重排
描述
给定一个单链表,请设定一个函数,将链表的奇数位节点和偶数位节点分别放在一起,重排后输出。
注意是节点的编号而非节点的数值。
F1:双指针
思路
第一个节点是奇数位,第二个节点是偶数位,第三个节点又是奇数位,因此,可以断掉节点 1 和节点 2 之间的连接,节点 1 的 next 指向节点 2 后面的节点 3。断掉节点 2 与节点 3 之间的连接,指向节点 4 节点,如此直到链表结束。
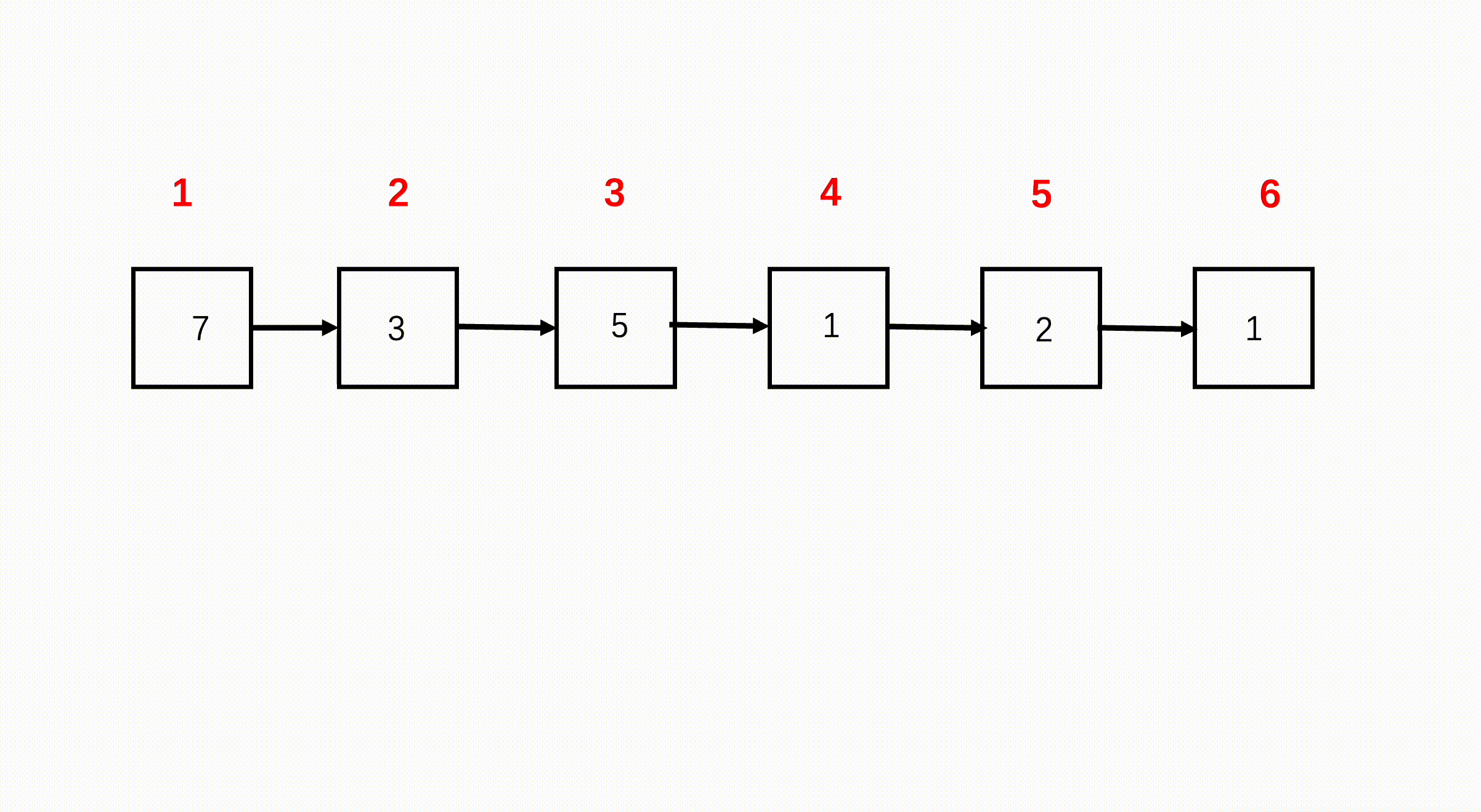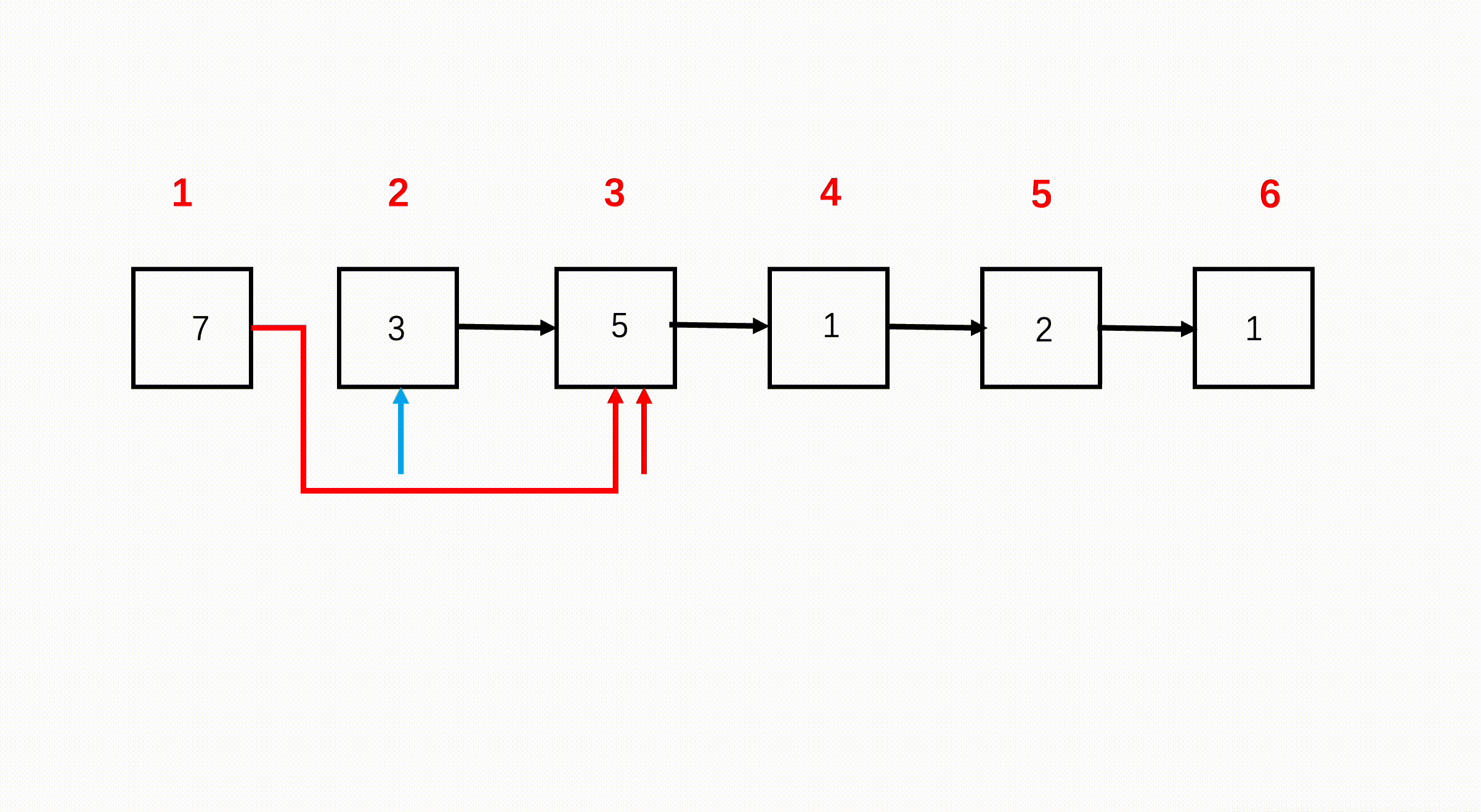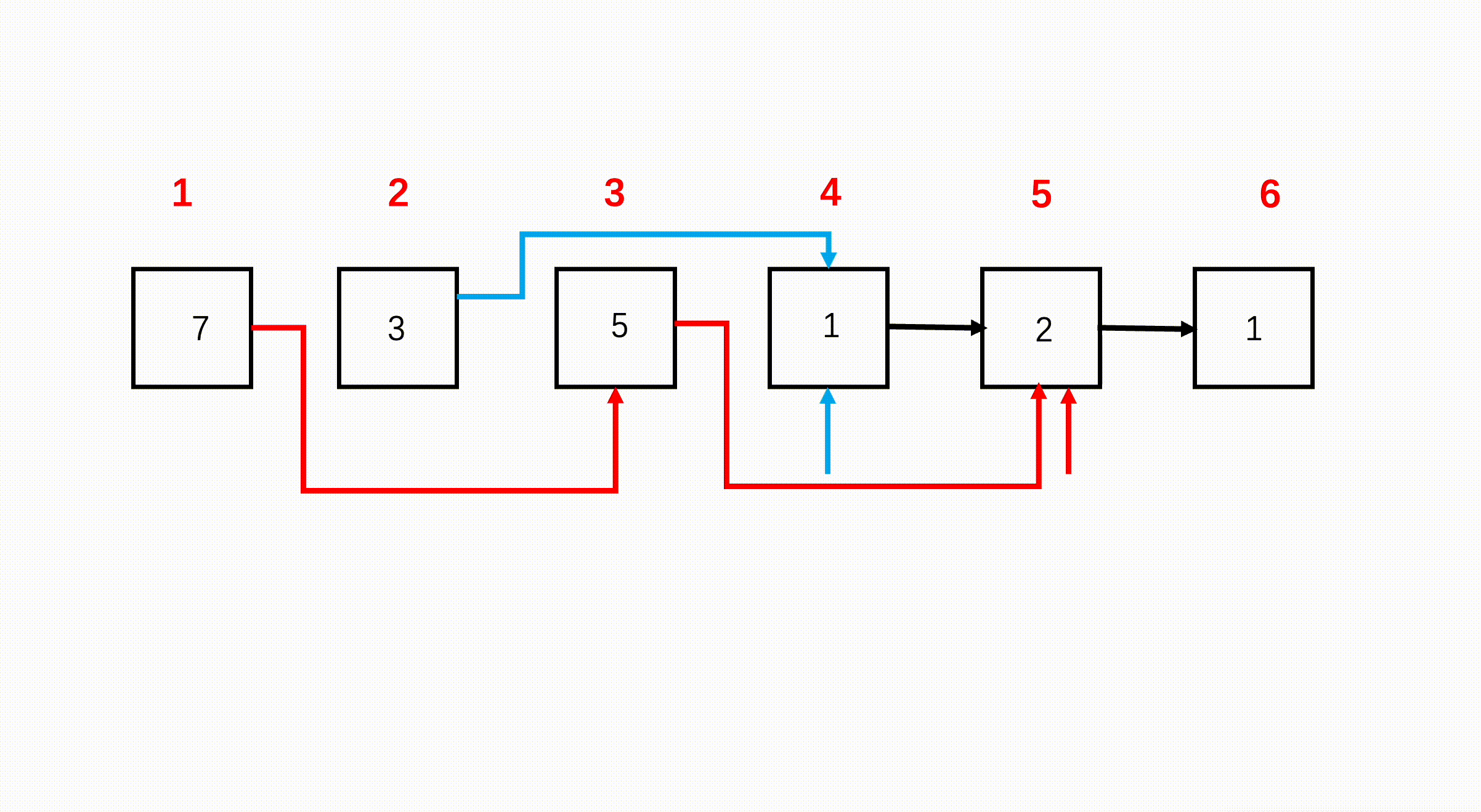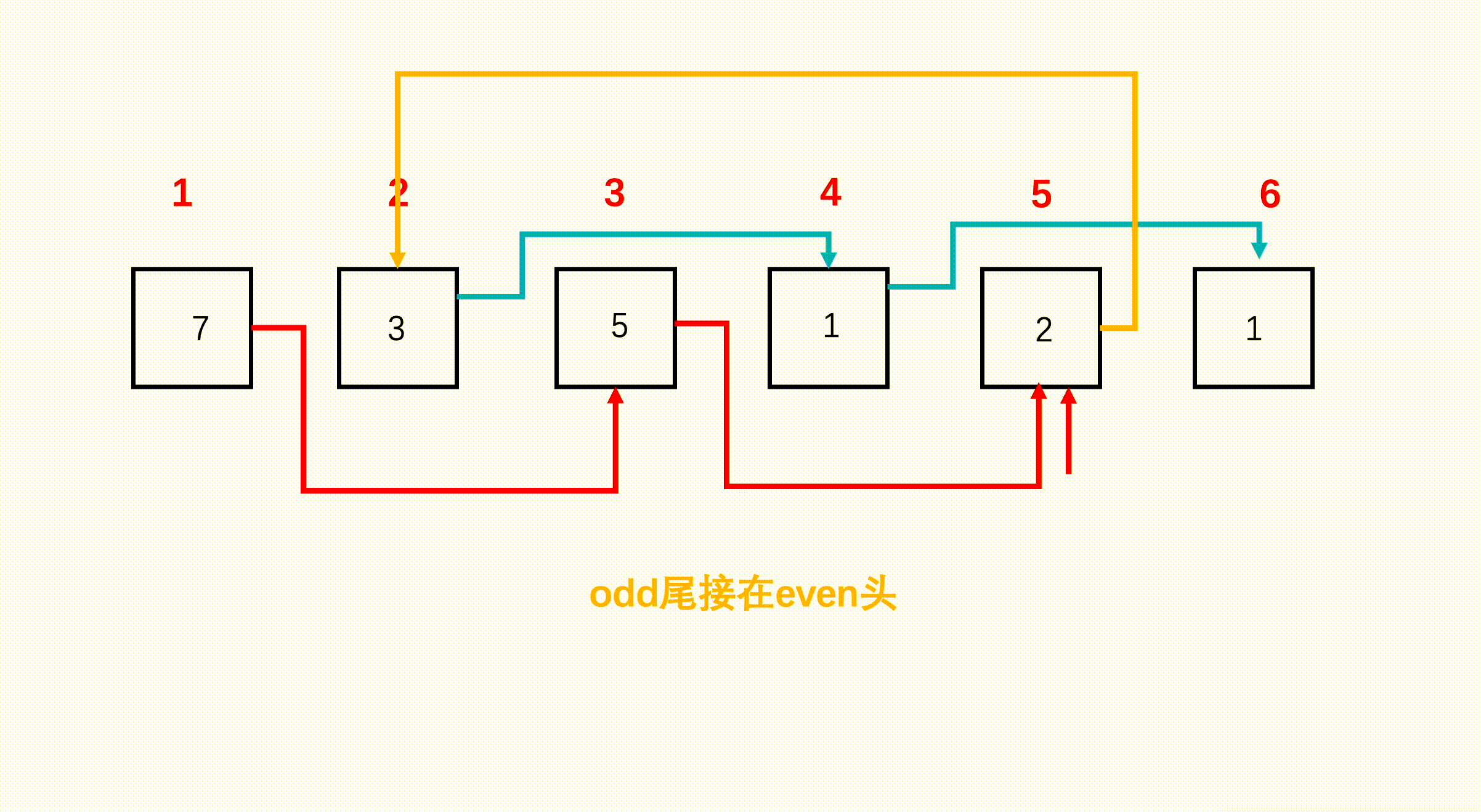
步骤
判断空链表的情况,如果链表为空,不用重排。
使用双指针 odd 和 even 分别遍历奇数节点和偶数节点,并给偶数节点链表一个头。
上述过程,每次遍历两个节点,且 even 在后面,因此每轮循环用 even 检查后两个元素是否为 null,如果不是,再进入循环进行上述连接过程。
将偶数节点头接在奇数位最后一个节点后面,再返回头部。
代码
1 | public ListNode oddEvenList(ListNode head) { |
时间复杂度
\(O(n)\)
遍历一次链表所有节点。
空间复杂度
\(O(1)\)
常数级指针变量,没有额外辅助空间。
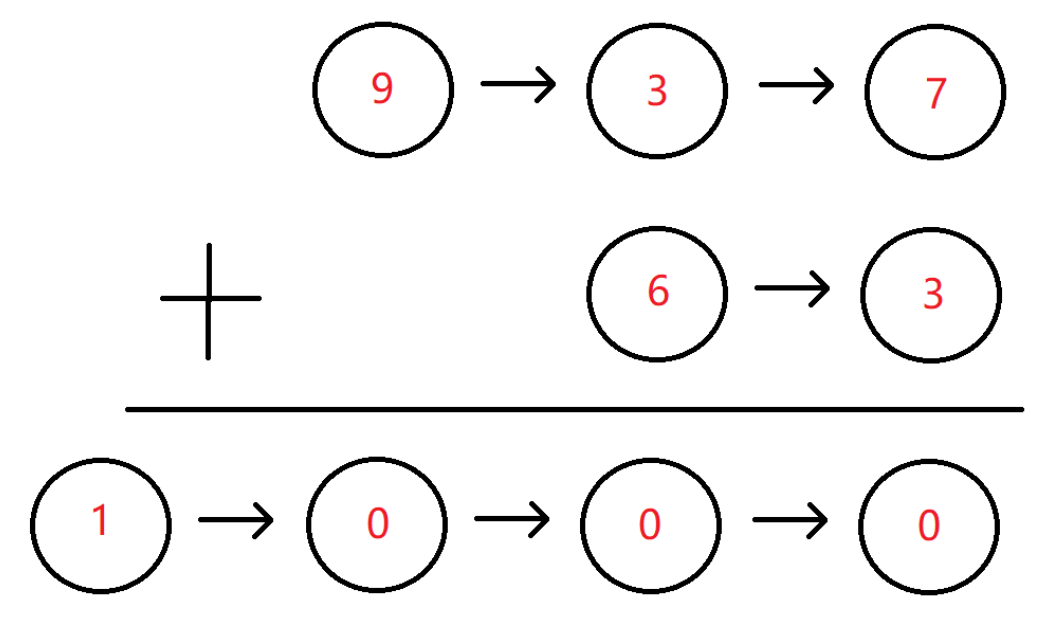
BM11 链表相加(二)
描述
假设链表中每一个节点的值都在 0 - 9 之间,那么链表整体就可以代表一个整数。
给定两个这种链表,请生成代表两个整数相加值的结果链表。
例如:链表 1 为 9->3->7,链表 2 为 6->3,最后生成新的结果链表为 1->0->0->0。
F1:反转链表
思路
链表无法逆序遍历,我们可以将两个链表都反转,然后进行相加运算。
步骤
- 任意一个链表为空,返回另一个链表即可,因为链表为空相当于 0。
- 反转两个待相加的链表。
- 设置返回链表的链表头,设置进位 carry = 0。
- 从头开始遍历两个链表,直到两个链表节点都为空且 carry 也不为 1。每次取出不为空的链表节点值,为空就设置为 0,将两个数字与 carry 相加,然后查看是否进位,将进位后的结果(对 10 取模)加入新的链表节点,连接在返回链表的后面,并继续向后遍历。
- 返回前将结果链表再反转回来。

代码
1 | public ListNode addInList(ListNode head1, ListNode head2) { |
时间复杂度
\(O(max(m,n))\)
其中 m 与 n 分别为两个链表的长度,反转链表三次,复杂度分别为 \(O(n)\)、\(O(m)\)、\(O(max(m,n))\),相加过程也是遍历较长的链表。
空间复杂度
\(O(1)\)
常数级指针变量,没有额外辅助空间,返回的新链表属于必要空间。
BM12 单链表的排序
描述
给定一个节点数为n的无序单链表,对其按升序排序。
F1:归并排序
思路
如何合并呢?
在合并阶段可以参考 BM4 合并两个有序链表,两个链表逐渐取最小的元素即可。
如何划分呢?
常规数组的归并排序是分治思想,即将数组从中间元素开始划分,然后将划分后的子数组作为一个要排序的数组,再将排好序的两个子数组合并成一个完整的有序数组,因此采用的是递归。
在链表中,我们也可以使用同样的方式,只需找到中间节点的前一个节点,将其断开,就可以将链表分成两个子链表,然后继续划分,直到最小,然后向上依次合并。
- 终止条件:当子链表划分到为空或者只剩一个节点时,不再继续划分,向上合并。
- 返回值:每次返回两个排好序且合并好的子链表。
- 本级任务:找到这个链表的中间节点,从前面断开,分为左右两个子链表,进入子问题排序。
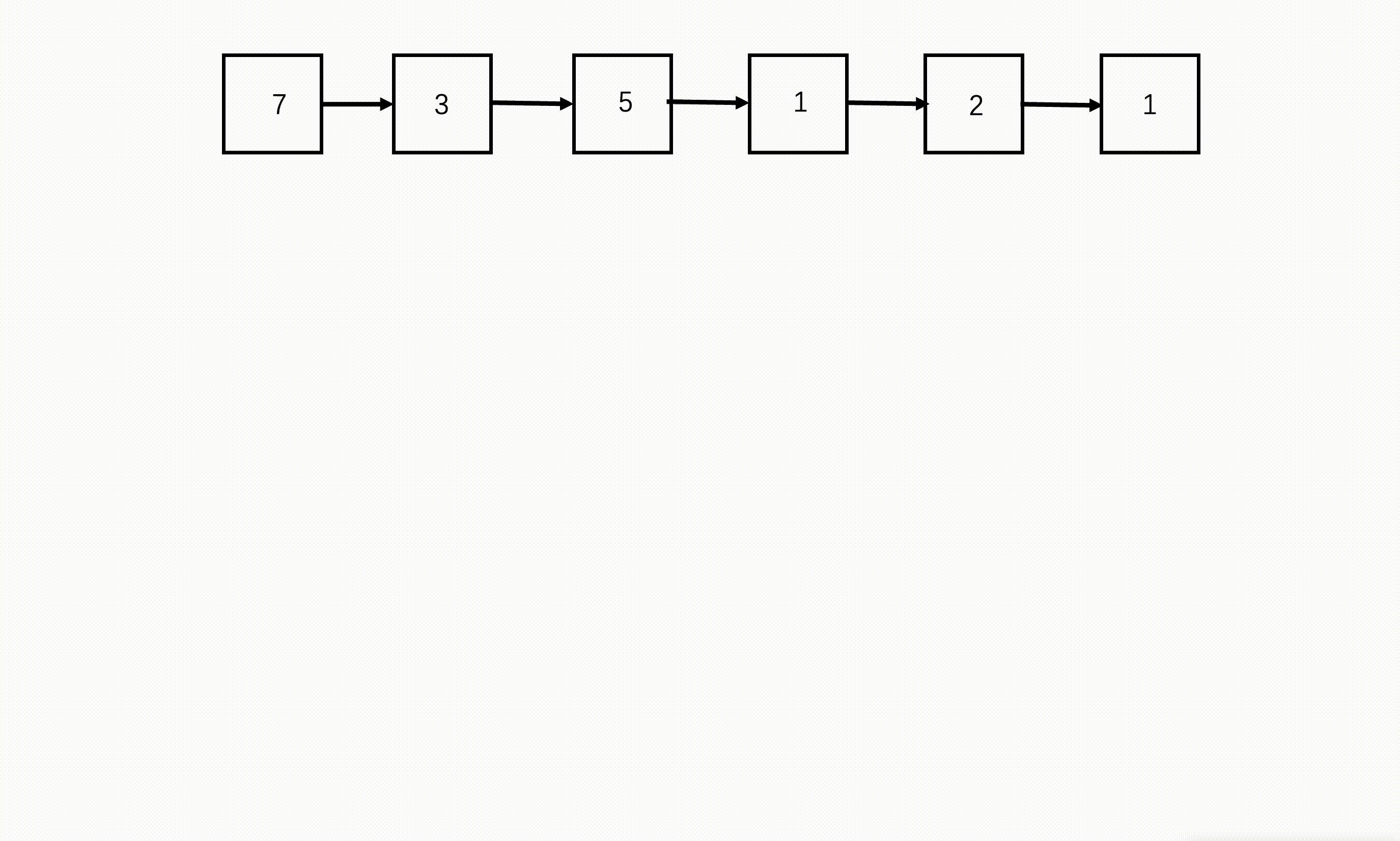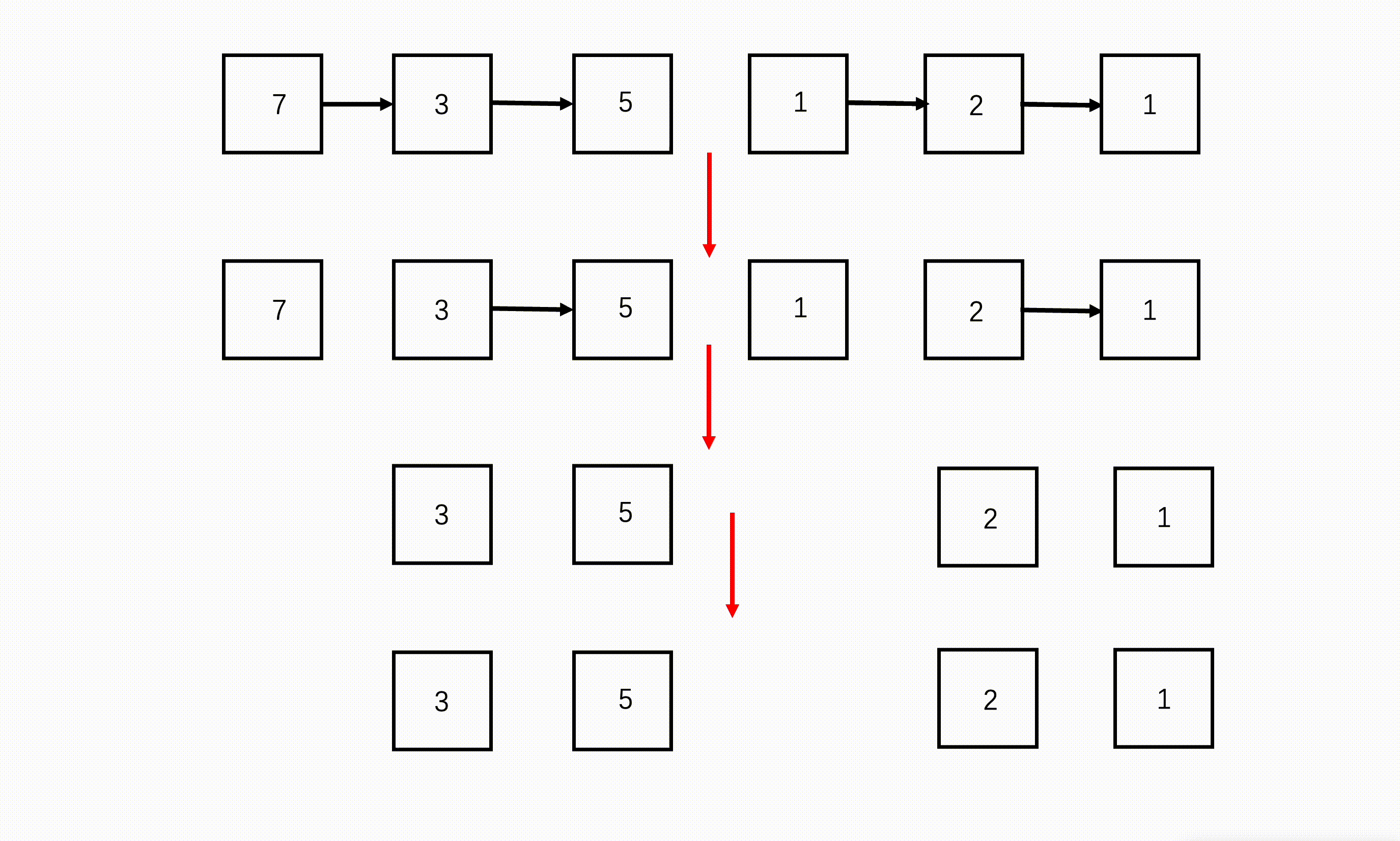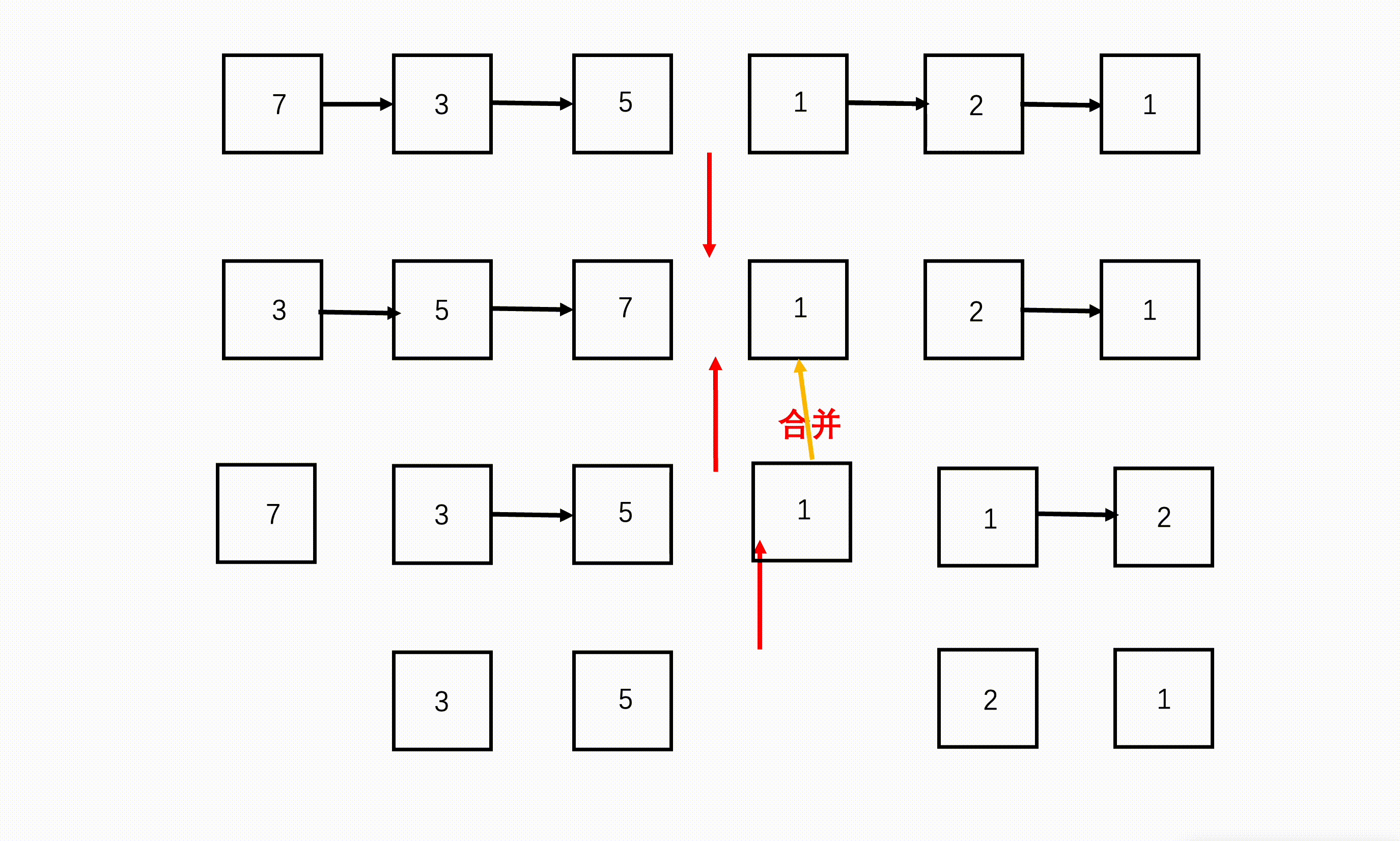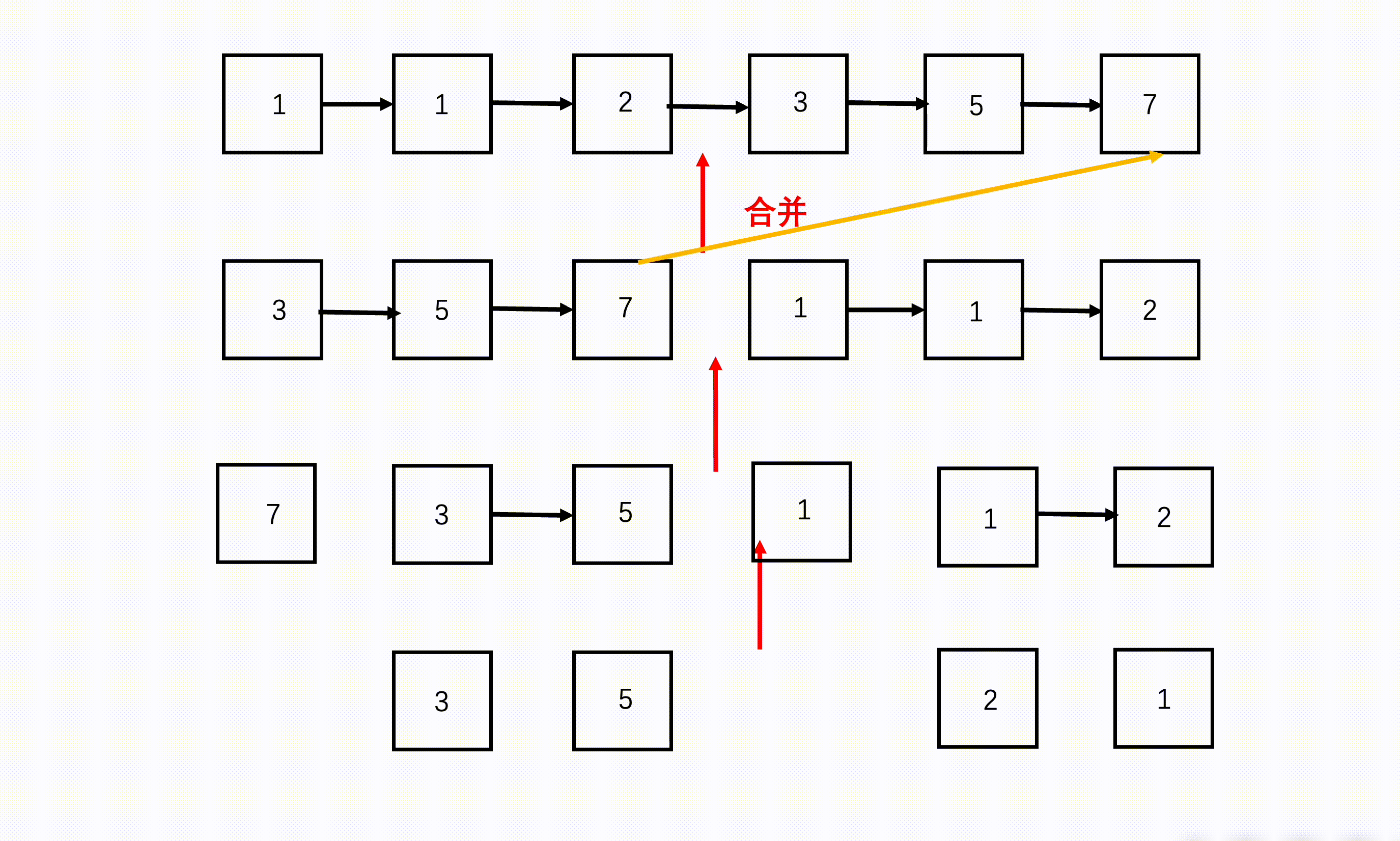
如何找中间节点呢?
可以参靠 BM13 判断一个链表是否是回文结构 的方法 2 双指针寻中法,快指针每次两步,慢指针每次一步,当快指针到达链表尾的时候,慢指针正好走了快指针距离的一半,为中间节点。
步骤
- 首先判断链表为空或者只有一个元素,直接就是有序的。
- 准备三个指针,快指针 right 每次走两步,慢指针 mid 每次走一步,前序指针 left 每次跟在 mid 前一个位置。三个指针遍历链表,当快指针到达链表尾部的时候,慢指针刚好走了链表的一半,正好是中间位置。
- 从 left 位置将链表断开,刚好分成两个子问题开始递归。
- 将子问题得到的链表合并。
代码
1 | public ListNode sortInList(ListNode head) { |
时间复杂度
\(O(nlog_2n)\)
每一级划分最坏需要遍历链表全部元素,因此 \(O(n)\),每一级合并都是将同级的子问题链表遍历合并,因此也为 \(O(n)\),分治划分为二叉树型,一共有 \(O(log_2n)\) 层,因此复杂度为 \(O((n + n) * log_2n)\) = \(O(nlog_2n)\)
空间复杂度
\(O(log_2n)\)
递归栈的深度最坏为树形递归的深度,\(log_2n\) 层。
F2:转化为数组排序
思路
链表无法按照下标访问,只能逐个遍历,因此像排序中的快速排序、堆排序都无法使用,只能使用一次遍历的冒泡排序、选择排序这些。但是这些 \(O(n^2)\) 复杂度的排序方法太费时间了,我们可以将其转化成数组后再排序。
步骤
- 遍历链表,将节点值加入数组。
- 使用内置的排序函数对数组进行排序。
- 依次遍历数组和链表,按照位置将链表中的节点值修改为排序后的数组值。
代码
1 | public ListNode sortInList(ListNode head) { |
时间复杂度
\(O(nlog_2n)\)
sort 函数一般为优化后的快速排序,复杂度为 \(O(nlog_2n)\)。
空间复杂度
\(O(n)\)
存储链表元素值的辅助数组长度 n。