MySQL索引
将多个字段组合成一个索引,这个索引就是联合索引。联合索引会按照「最左匹配」原则,进行索引匹配。
在联合索引的范围查询中,遇到 >、< 会停止匹配,范围查询的字段可以使用联合索引,但是范围查询字段后面的字段就无法使用了,而对于 >=、<=、BETWEEN、like 前缀匹配的范围查询,并不会停止匹配。
MySQL 5.6 引入了索引下推优化,可以在联合索引遍历过程中,对联合索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
在建立联合索引时,要把区分度大的字段排在前面,效率更高。MySQL 有查询优化器,如果字段在表的数据行中占比超过界限(30%),会忽略索引,进行全表扫描。
索引的最大好处就是能够提高查询速度,但是创建索引和维护索引不仅耗时,索引还会占用空间,并且因为要动态维护索引而降低增删改的效率。
推荐对唯一字段、用于 WHERE、GROUP BY、ORDER BY 的字段建立索引,不推荐对数据量很小的表、存在大量重复数据的字段以及经常更新的字段建立索引。
联合索引
联合索引
将多个字段组合成一个索引,这个索引就是联合索引。
CREATE INDEX idx_product_no_name ON product(product_no, name);
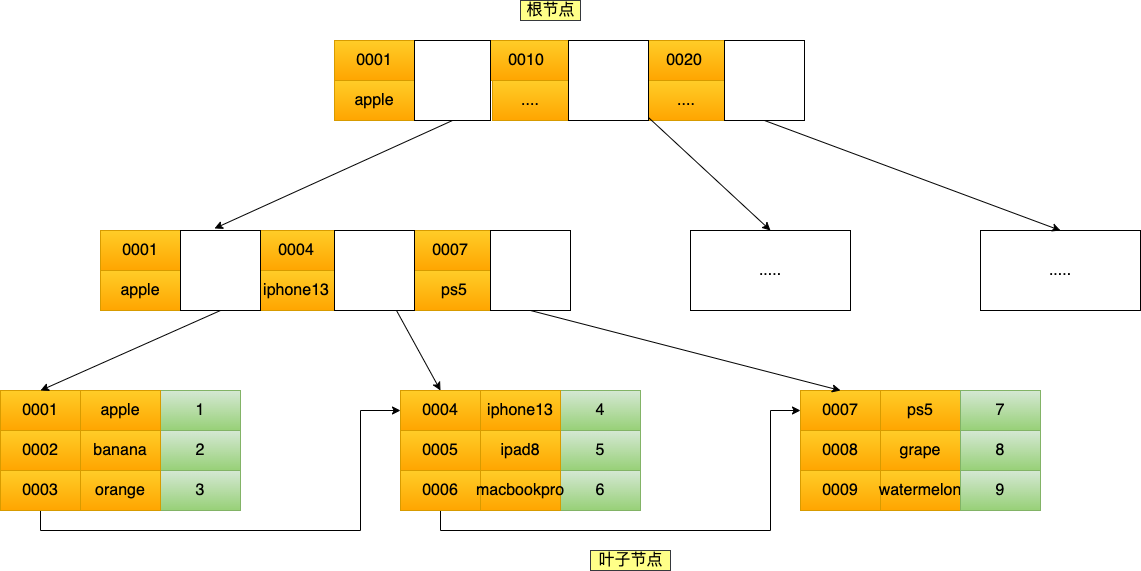
联合索引使用两个字段的值作为 key(黄色部分),按照最左匹配原则,进行索引匹配。如果不遵循「最左匹配原则」,联合索引会失效。
最左匹配原则
假设创建了一个联合索引 (a, b, c),联合索引生效的例子如下:
1 | where a = 1; |
因为有查询优化器,所以 a 字段在 where 子句的顺序并不重要。
联合索引失效的例子如下:
1 | where b = 2; |
失效原因是,(a, b, c) 是联合索引,先按 a 排序,在 a 相同的情况再按 b 排序,在 b 相同的情况再按 c 排序。所以,b 和 c 是全局无序,局部相对有序。如果没有遵循最左匹配原则,是无法利用索引的。
下面是联合索引(a, b)的 B+ Tree。
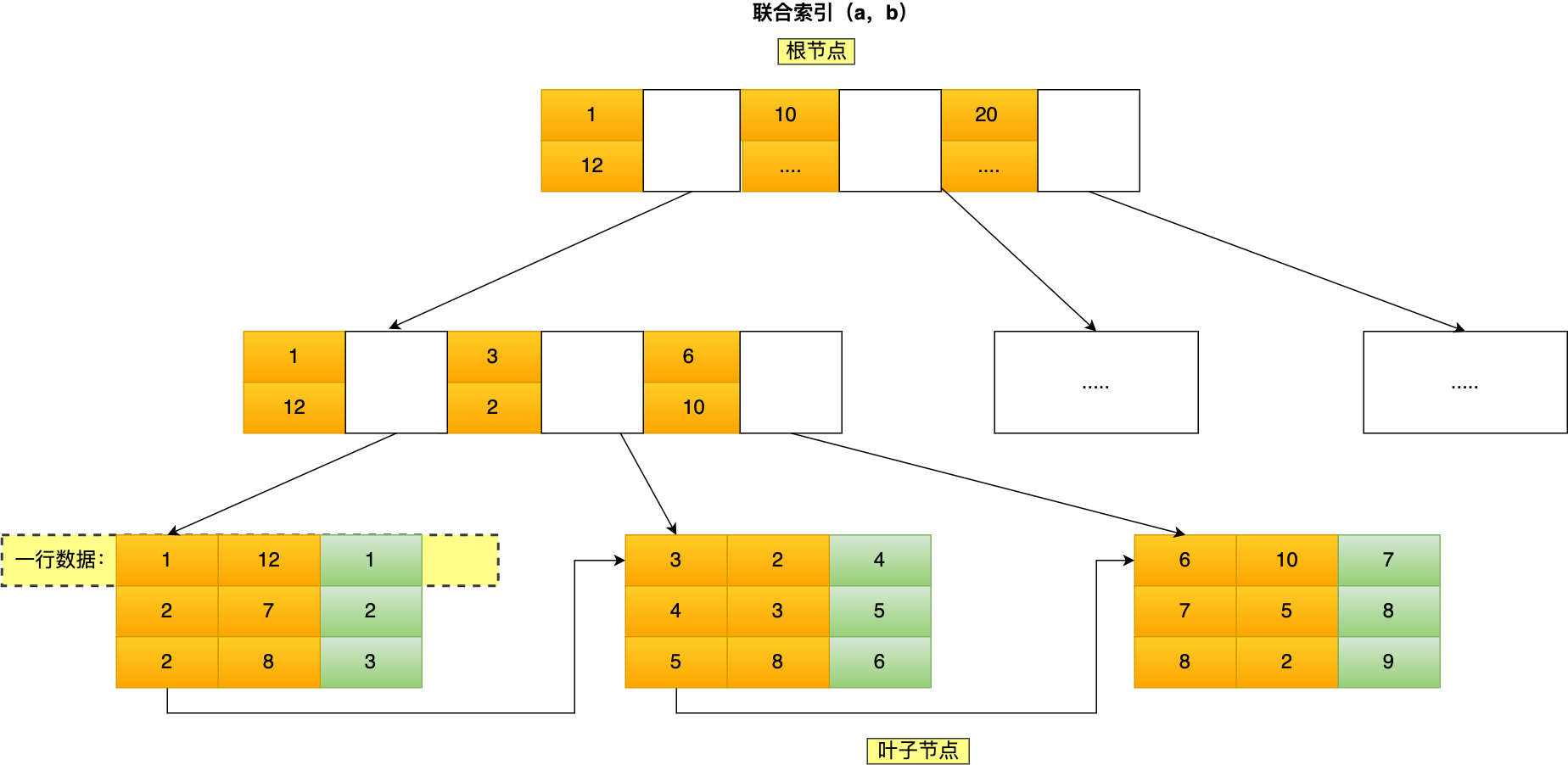
索引 a 全局有序 (1, 2, 2, 3, 4, 5, 6, 7, 8),而索引 b 全局无序(12, 7,
8, 2, 3, 8, 10, 5, 2)。因此,直接执行 where b = 2
这种查询条件是无法利用联合索引的,利用索引的前提是,索引里的 key
是有序的。
只有在索引 a 相同的情况下,索引 b 才是有序的,比如 a = 2 时,b 的值是
(7, 8),这时就是有序的,这个有序状态是局部的,因此,执行
where a = 2 and b = 7 是 a 和 b
字段能用到联合索引,也就是联合索引生效了。
联合索引范围查询
联合索引有一些特殊情况,并不是查询过程使用了联合索引,就代表联合索引中的所有字段都用到了联合索引进行索引查询,可能存在部分字段用到联合索引,部分字段没有用到的情况。
这种特殊情况发生在范围查询。联合索引的最左匹配原则会从左到右匹配直到遇到「范围查询」就会停止匹配。即,范围查询的字段可以用到联合索引,但是在范围查询字段的后面的字段无法用到联合索引。
范围查询有很多种,哪些范围查询会导致联合索引的最左匹配原则会停止匹配呢?
联合索引的最左匹配原则,在遇到范围查询(如 >、<)的时候,就会停止匹配,也就是范围查询的字段可以用到联合索引,但是在范围查询字段的后面字段无法用到联合索引。
对于 >=、<=、BETWEEN、like 前缀匹配的范围查询,并不会停止匹配。
索引下推
对于联合索引 (a, b),在执行
select * from table where a > 1 and b = 2; 语句时,只有
a 字段能用到索引,在联合索引的 B+ Tree 找到第一个满足条件的主键值(a =
2)后,还需要判断其他条件是否满足(看 b 是否等于
2),那是在联合索引里判断?还是回主键索引去判断?
在 MySQL 5.6 之前,只能从主键值(a = 2)开始一个个回表,到「主键索引」上找出数据行,再对比 b 字段值。
MySQL 5.6 引入了索引下推优化,可以在联合索引遍历过程中,对联合索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
当你的查询语句的执行计划里,出现了 Extra 为
Using index condition,那么说明使用了索引下推的优化。
索引区分度
联合索引的字段顺序,对索引效率有很大的影响。越靠前的字段被用于索引过滤的概率越高,因此建立联合索引时,要把区分度大的字段排在前面,这样区分度大的字段越有可能被更多的 SQL 使用到。 \[ 区分度 = \frac{distinct(column)}{count(*)} \] \(distinct(column)\): 某个字段 column 不同值的个数,\(count(*)\): 表的总行数。
比如,性别的区分度就很小,不适合做索引或排在联合索引列靠前的位置,而 UUID 就区分度就很大,就很适合。
MySQL 有一个查询优化器,如果发现某个值在表的数据行中的百分比(惯用界限 30%)很高时,会忽略索引,进行全表扫描。
索引使用场景
索引优缺点
优点
提高查询速度
缺点
1、需要占用物理空间,数量越大,占用空间越大;
2、创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增大;
3、会降低表的增删改的效率,因为每次增删改索引,B+ 树为了维护索引有序性,都需要动态维护。
推荐使用场景
1、字段有唯一性限制的,比如订单号;
2、经常用于 WHERE
查询条件的字段,如果查询条件不是一个字段,可以建立联合索引。
3、经常用于 GROUP BY 和 ORDER BY
的字段,这样在查询的时候就不需要再做一次排序了,因为建立索引后在 B+ Tree
中的记录都是排序好的。
不推荐场景
1、WHERE、GROUP BY、ORDER BY 用不到的字段;
2、字段存在大量重复数据,比如性别字段,MySQL 查询优化器会忽略该索引进行全表扫描;
3、表数据太少;
4、经常更新的字段,比如用户余额,因为要动态维护索引,影响数据库性能。